
Introduction
Understanding synchrony between groups of people is the new ongoing research topic in the computer science field. Different machine learning techniques are being explored to analyze group formation. There have been ongoing research works on how supervised methodologies, unsupervised methodologies, as well as reinforcement learning can be applied to understand interactional synchrony. In this study, we will be exploring different types of regression algorithms for the understanding of group formation for the GFT data.
Regression is an element of the supervised learning method. Regression is a mechanism to evaluate and understand the nature of the given data. There several kinds of regression that can be applied to the data. It is essential to choose the correct regression mechanism that best suits the data to be able to extract useful information and predict the correct outcomes. The data variables and data dimensionality are the two important elements in choosing a regression method. Cross-validation is used to evaluate the efficiency of the regression method [11]. Random forest regression and gaussian regression models are explored in this study.
To experiment in the right direction with the dataset, it is important to visualize and understand the nature of the data. The graphical depiction of the data creates a better understanding of the information in the data. In this study, principal component analysis and t-distributed stochastic neighbor embedding tools are used for visualizing the data concerning different variables [10].
In this study, past research studies on interactional synchrony are explored, the dataset used for the experiment is described, the extraction of various features from the dataset is explained, a brief overview of the data cleaning process is mentioned, the different regression algorithms and visualization techniques are explained along with the results obtained.
Literature Survey
Interactional synchrony indicates the momentary form of coordination that takes place when two or more people communicate with each other. Most of the people are naturally social. Research has determined that interactional synchrony is formed based on the understanding between people. Nwogu et al. [4] have used a computer vision approach to determine interactional synchrony between people, using facial expressions. [4] illustrates a highly effective system with the use of a long short-term memory (LSTM) mechanism to determine and analyze synchrony between people.
Many existing methodologies demand labeled data and mainly concentrate on a single entity rather than the entire situation to analyze the interaction between people. [1] proposes an unsupervised method using a branch and bound technique that allows an exhaustive search to determine an optimal solution for synchrony between humans. Their research has proved that unsupervised methodologies are also equally efficient in synchrony detection as the supervised methodologies.
Human behavior is not always truthful. It is essential to study the level of deception in synergy as sometimes frauds can exploit others in the situation. [5] contributes to an automated evaluation of interactional synchrony that comprises of vigorous facial tracking mechanism, identifying facial expressions, feature extraction, and feature selection. The proposed system not only effectively determines interactional synchrony but also the features obtained during the experiment help to determine the level of deception present in the interaction.
Methods that require analysis of each individual to determine the synchrony are usually complicated and time-consuming as they demand exhaustive coding, annotation, and segmentation. Automated methods help to solve issues arisen mentioned previously. Cohen et al. [2] mention that the features and the measures are the two essential entities for determining interactional synchrony. Features such as facial expressions, body gestures, head movement, etc. are critical for the study. A popular method used to determine interactional synchrony is to apply cross-correlation on various extracted features on the fixed duration of synergy.
Applying the knowledge from the past, in this paper, different regression algorithms are investigated to analyze and understand the dynamics of group formation and interactional synchrony between people.
Datasets
- Data Collection
GFT dataset comprises 172800 video frames of 32 groups of people, communicating with each other where each group contained 3 people each, annotations based on the Facial Action Coding System (FACS), basic results of the experiment, and a data file that describes the dataset. 96 different members were gathered in 32 groups of 3 members each and given a glass of drink each, for the experiment to collect the data which formed the GFT dataset. All the members were new to each other. There were groups with mixed genders as well as the same genders. Some groups were given alcoholic drinks and some non-alcoholic drinks. Each group of people was given a glass of drink and was requested to communicate with each other for a particular time. 1 minute of the data where people in the group got most comfortable with each other was added to the GFT dataset. FACS Intensity data file was created where each frame of the video collected for each person was annotated with the level of presence of 5 of the facial action units (AUs) that will be explained in the later section [7]. The usage of the GFT dataset, in this independent study, will be explained in the later sections.
- Annotating Synchrony
Annotation data was collected by surveying different people. The respondents were given sets of video clips from the GFT dataset. Each set of videos comprised of a video where 3 people were interacting (persons A, B, and C) and 3 close-up videos of A, B, and C. The respondents were required to watch each set of videos, analyze the interactional synchrony between pairs of people (AB, BC, and AC) and rate each pair for each set of videos, according to the following rating scale:
- The people are meeting for the first time and not trying to form a group.
- The people are meeting for the first time and are trying to form a group.
- The people know each other.
- The people know each other and are in the process of forming a group.
- The people know each other well and already function well as a group.
Each set of videos, for example, videos “001”, “001A”, “001B” and “001C” was rated by 3 different respondents. There was a total of 31 sets of videos and, a collection of 31*3 ratings for the pairs AB, AC and, BC was gathered. To remove any misleading ratings, an agreement algorithm was applied to the collected data to measure the inter-rater reliability of the 3 raters for each set of the video. Equation (1) was used to calculate the degree of agreement among the raters for each set of videos. The threshold was kept as “50”. If the relative standard deviation was above “50”, an opinion from the 4th rater was taken. Then, the data for the rater with a disagreement was eliminated and replaced with the data collected from the 4th rater. For each set of video and pair, one rating value was obtained by averaging the ratings of the 3 raters. This resulted in a single rating for each pair of people in each set of videos. This data is considered as the ground truth values.
Relative Standard Deviation = (standard deviation/mean) * 100 (1)
Working with Facial Action Coding System (FACS) Intensity Data
The dataset used to investigate the patterns of group formation is the GTF - FACS Intensity data [7]. This data comprises of 93 CSV files, where each file contains values of the facial action units (AU) 1, 6, 10, 12, and 14 of that particular person. The AUs are used to extract information about the emotions of a particular person. AU 1 describes the “Inner Brow Raiser”, AU 6 describes the “Cheek Raiser”, AU 10 describes the “Upper Lip Raiser”, AU 12 describes the “Lip Corner Puller” and AU 14 describes the “Dimpler” [3]. There were originally 96 CSV files in the dataset. However, 3 of the files representing a particular group conversation had some erroneous and missing data. Thus, the 3 files were left out from the investigation process in this study.
The 93 CSV files represent the AU information of the 93 people who took part in the experiment. Three people were made to form a group, and the groups are numbered from 1 to 31. Each of the 3 people in a group is represented by A, B, and C respectively. The people in group 1 are represented by files “001A_int.csv”, “001B_int.csv” and, “001C_int.csv”. For the 31 groups, there is a total of 31*3 files, which equals 93 files. The files are named in the following convention:
- 001A_int.csv: This file contains the AU information of person A in group 1.
- 0010B_int.csv: This file contains the AU information of person B in group 10.
- 0023C_int.csv: This file contains the AU information of person C in group 23.
Each file has 1800 rows, which represents 1800 time frames recorded during a group conversation. Each row represents the AU of that person at that particular time frame. Since the data for all the AUs for all three people in a group were annotated for that particular time frame, a particular row in all the 3 files of the people in a group represents their AU at the same time frame. From examining AUs of all the three people at a particular time frame, information such as how the conversation was going on, how the three people were interacting, and how well they had jelled up can be extracted.
- Methodology to obtain feature vectors
To make any use of the data files mentioned earlier, the files with raw data had to be converted into feature vectors. Figure 1 shows the methodology used to convert each CSV file into a feature vector.
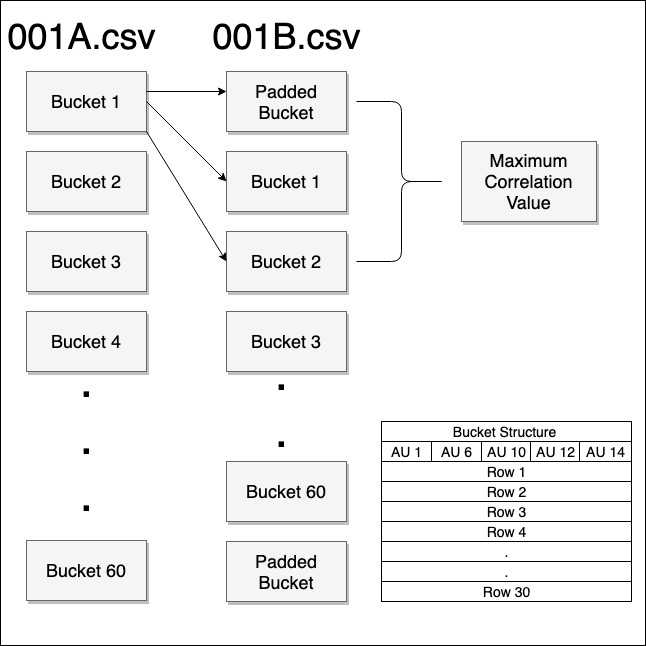
Figure 1: Conversion of data from CSV format into feature vectors
The 1800 frames in each of the files were divided into buckets of 30-time frames each. Thus, each file was converted into 60 buckets each. Each bucket is a 30*5 vector, where each row was a time frame, and the 5 columns corresponded to the 5 AUs. For each group, the later discussed mechanism was applied. For the interaction between person A and person B, the files “001A_int.csv” and “001B_int.csv” were converted into 60 buckets each. The values of AU 1 of Bucket 0 of person A, was correlated with the following data:
- values of AU 1 of the padded bucket of person B
- values of AU 1 of Bucket 1 of person B
- values of AU 1 of Bucket 2 of person B
The padded buckets were filled with ‘0’ for all the rows. The maximum of the above mentioned 3 values was taken and was marked as the correlation value between A and B for AU 1 of bucket 1. A similar process for bucket 1 of person A was carried out for the other AUs 6, 10, 12, and 14. This process resulted in a 1*5 vector which represents the correlation between person A and person B for bucket 1 of person A. Similarly, 1*5 vectors were generated for all the 60 buckets of person A, resulting in a 60*5 vector to represent the overall correlation between person A and B of the group “001”. A column-wise maximum, a column-wise mean, and a column-wise standard deviation was taken on this 60*5 vector and were all appended together resulting in a 1*15 vectors that represent the interaction and rapport between person A and B of the group “001”.
The above process of generating the 1*15 vector was repeated between (person B, person C) and (person C, person A). In the end, a 3*15 vector was generated to represent the overall interaction between persons A, B, and C of the group “001”. A similar technique was used on all the other 30 groups. Using this above process, the 93 CSV files were converted into 93*15 vector where: row 1: represents (A, B) of the group “001”, row 2: represents (B, C) of the group “001”, row 3: represents (A, C) of the group “001” and so on.
- Data Cleaning
The value ‘0’ conveys the absence of a particular AU and, ‘9’ conveys the AU is unknown for that particular time frame. To obtain correct results, the data files were cleaned during the process of obtaining feature vectors. During the calculation of the correlation between the buckets, if a bucket met the following conditions mentioned below, those buckets were omitted in the calculation.
- number of 0’s greater than 15
- number of 9’s greater than 15
- number of 0’s and 9’s greater than 15
Regression Algorithms
The annotated data mentioned in the previous sections were used as the ground truth values. Every row in the 93*15 vector was an input data point (X), and the corresponding value in the annotated data file was considered as the true label (Y). The data was split for the training and testing using the 80:20 ratio, respectively. Both the normal cross-validation and 5-fold cross-validation were performed on the regression models.
- Random Forest Regression
In machine learning, outputting a result of a combination of predictions from different methodologies is called ensemble learning. Random forest regression follows the ensemble mechanism using the “bagging” methodology. “Bagging” trains the different decision trees on different samples of data with restoration in the sampling process. Fundamentally, the output from each decision tree is combined through an “average” function to make the final prediction [8]. In this implementation, a random forest regressor was fit on 80% of the data and performed a prediction on the other 20% of the data.
- Gaussian Process Regression
Gaussian process regression is a measure of the probability distribution over all the relevant operations that predicts outcomes for the given data. Gaussian process regression works on the “Bayesian” method used to examine the data and produce predictions when given a scenario. A previous distribution over the data is used along with some training observations to produce the following distributions to make predictions. The kernels used in the gaussian process regression are Radial-basis function (RBF), and Constant as shown in (2) [9]. In this experiment, a Gaussian process regressor was fit on 80% of the data and performed a prediction on the other 20% of the data.
Kernel = RBF() * Constant() (2)
Results
Random forest regression and gaussian process regression algorithms were evaluated for this dataset. Random predictions were generated (from 1 to 5) and tested with normal cross-validation as the baseline test error results. The ground truth values that were collected were used to obtain the error results. Table I shows the test error results obtained from performing normal cross-validation and 5-fold cross-validation on the ‘test’ data and normal cross-validation on the ‘train’ data for the different algorithms. From the results obtained, it can be concluded that both the random forest regression and gaussian process regression algorithms have been trained for the dataset as the test error is much lower when compared to the error obtained from random predictions. Further, it can be observed that the random forest regression performs twice as better as random predictions and, the gaussian process regression performs 50% better than the random predictions. For this dataset, random forest regression helped to better understand the interactional synchrony between the people.
| Normal cross-validation (test data) | 5-fold cross-validation (test data) | Normal cross-validated (train data) |
Random Forest | 0.725 | 0.880 | 0.379 |
Gaussian Process | 1.011 | 1.210 | 5.505e-11 |
Random Predictions | 1.603 | - | - |
Table I: Test error results for the different algorithms
Conclusion
In this independent study, different regression algorithms were applied to the existing GFT data along with the synchrony annotation data collected to understand the interaction synchrony between people. Random forest regression algorithm, most appropriately fitted to the dataset in extracting the level of synchrony between people. In this independent study, the analysis of synchrony was performed only on groups of 2 people. In the future, analysis is aimed to be performed on groups of 3 people. The work will also be extended to train with deep learning models such as convolutional neural networks and recurrent neural networks to classify interactions of people into different categories.
References
[1] W. Chu, J. Zeng, F. De la Torre, J. F. Cohn, and D. S. Messinger. Unsupervised Synchrony Discovery in Human Interaction. In 2015 IEEE International Conference on Computer Vision (ICCV), pages 3146–3154, 2015.
[2] E. Delahaerche, M. Chetouani, and D. Cohen. Interpersonal Synchrony: A Survey of Evaluation Methods Across Disciplines and its Application to ASD. Neuropsychiatrie de l’Enfance et de l’Adolescence, 60:S32–S33, 07 2012.
[3] B. Farnsworth. Facial Action Coding System (FACS) – A Visual Guidebook. IMOTIONS, Aug 2019.
[4] N. Watkins and I. Nwogu. Computational Social Dynamics: Analyzing the Face-level Interactions in a Group. CoRR, abs/1807.06124, 2018.
[5] X. Yu, S. Zhang, Y. Yu, N. Dunbar, M. Jensen, J. K. Burgoon, and D. N. Metaxas. Automated Analysis of Interactional Synchrony using Robust Facial Tracking and Expression Recognition. In 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), pages 1–6, 2013.
[6] L. Derksen. Visualising High-dimensional Datasets using PCA and t-SNE in Python. Towards Data Science, Oct 2016.
[7] J. Girard, W.-S. Chu, L. Jeni, J. Cohn, F. De la Torre, and M. Sayette Group Formation Task (GFT) - Spontaneous Facial Expression Database. volume 2017, 05 2017.
[8] Krishni. A Beginners Guide to Random Forest Regression. Medium, Nov 2018.
[9] Sit. H. Quick Start to Gaussian Process Regression. Medium, Jun 2019.
[10] Stewart. M. The Power of Visualization. Medium, May 2019.
[11] Ray. S. 7 Regression Techniques you should know. Analytics Vidhya, Aug 2015.










