Introduction
NLP classifiers has shown great success in many online appliactions. While such models report high accuracy, many times such machine learning NLP models suffer from unintended bias. Models are usually trained on human-generated texts and therefore would mirror the bias embedded in the imbalanced training datasets.
In this article, I focus on the problem of mitigating such unintended bias for a toxic text classification task, where toxicity is defined as anything rude, disrespectful or hateful. I'll experimwnt with different methods that have been claimed to be effective in mitigating bias in NLP applications. These methods will be applied to a toxic text classifier built to identify toxic online comments from the Civil Comments platform. The objective is to build an effective de-biased toxic text classifier and compare the de-biasing methods in the meantime.
Related Work
Bias in structured datasets has been studies from a perspective of detecting and handling imbalance. Khosla et al. propose a discriminative framework that directly exploits dataset bias during training for structured data. The previous literature is relatively rich when it comes to mitigating bias in structured imbalanced datasets.
However, little prior work exists on mitigating bias for text classification tasks. Dixon et al. is one of the first works that point out existing “unintended” bias in abusive language detection model and they show the bias can be greatly mitigated by adding more training samples. Bolukbasi et al. study gender bias in word embeddings and investigate techniques to alter the word embeddings and remove the bias embedded in the word vectors. But their work is restricted in gender-based stereotypes. Badjatiya et al. propose a two-stage framework to detect and mitigate the bias in text.
I'll experiment with the methods of augmenting dataset (Dixon et al., 2017) and the two-stage debias framework (Badjatiya et al., 2019).
Dataset
The dataset contains 1,804,874 comments from the Civil Comments platform, which shut down at the end of 2017. Each comment has a toxicity label, which indicates the probability of the comment being toxic. The probability is mapped into positive if it’s greater than 0.5, and negative if otherwise. Thus, the problem is converted into a simple binary classification problem.
A subset of comments has been labelled with a variety of identity attributes, representing the identities that are mentioned in the comment. Note that only identities with more than 500 examples will be included in the evaluation calculation.
The dataset is split into 80% train and 20% test sets. The trained model will be evaluated on test set.
Approach
1. Add non-toxic dataset
Since it is the imbalance in the training set that causes unintended bias. The first attempt is to add nontoxic, minority group related comments to training set. I hope these newly added data can bring certain identity terms in the original dataset to toxic/non-toxic balance. The non-toxic dataset is mined from Wikipedia articles by Dixon et al., 2018, containing 6000 comments about LGBT people. All the comments are evaluated by human raters to eliminate any potential hazard.
It's worth noting that the comments with regard to other entity groups are still highly imbalanced. To keep the comparison fair, I'll show the change of sub metrics for the homosexual_gay_or_lesbian group across different de-bias methods in the experiment results section.
2. Two-Stage De-biasing Approach
2.1 Stage 1: Identifying Bias Words
There are many methods to identify the bias words. Instead of building a classifier, a manually curated set of words from a related paper (Badjatiya 2019) is used to achieve more robust results:
lesbian, gay, bisexual, transgender, trans, queer, lgbt, lgbtq, homosexual, straight, heterosexual, male, female, nonbinary, african, african american, black, white, european, hispanic, latino, latina, latinx, mexican, canadian, american, asian, Indian, middle eastern, chinese, japanese, christian, muslim, jewish, buddhist, catholic, protestant, sikh, taoist, old, older, young, younger, teenage, millenial, middle aged, elderly, blind, deaf, paralyzed
2.2 Stage 2: Bias Correction Using Blurred Word Embeddings
Now that I have all the targeted words, the next step is to encode these words. I choose GloVe 200d to be the input vectors (Note that the baseline model use GloVe 100d). When encoding bias-sensitive words into vectors, instead of using their actual vectors, I use the centroid of its five nearest neighbors to “blur” the original word. For example, instead of using the actual GloVe word vector of the word “gay”, I'd input its nearest five neighbors’ centroid to the model as a representation of the word “gay”.
This approach is similar to one that uses a word’s parent word in WordNet to replace the word itself. It's hoped that a “blurred” vector could help the model to remove association between toxicity likelihood and certain identity attributes words.
Evaluation Metrics
To identity the unintended bias, I use a newly developed metric (Borkan et al., 2019) that combines several sub-metrics to balance overall performance with various aspects of bias.
The Final Metric is a score that combines the overall AUC with the generalized mean of the Bias AUCs. Note that Bias AUCs consists of three sub-metrics, namely Subgroup AUC, BPSN AUC, and BNSP AUC. The Final Metric is defined as below:
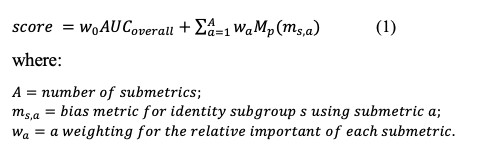
During the validation process, I evaluate the models using the final metric, as it would facilitate model training and tuning. However, sub-metrics for entitiy groups will be shown in the experiment results.
Experiment Results
To see the effect of each bias-mitigation method, I evaluate four models: a CNN baseline, a CNN baseline with added on-toxic dataset, a CNN baseline with non-toxic dataset and bias-mitigated embeddings, and an Bi-LSTM model with non-toxic dataset and bias-mitigated embeddings. The first three models are trained using an identical convolutional neural network architecture, while the last model is trained with a different architecture.
1. Baseline Model
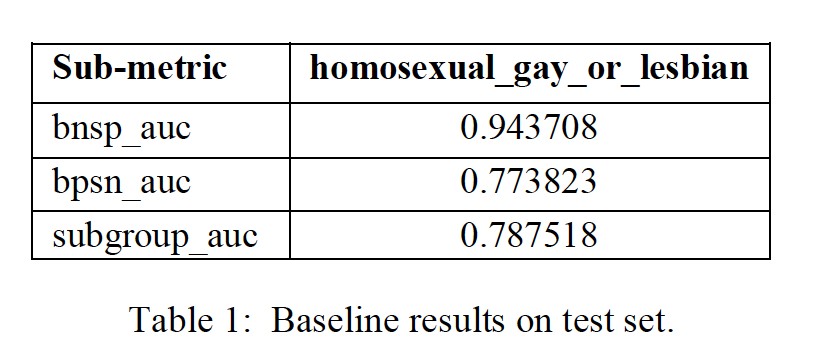
The baseline CNN model is trained on 1,443,899 supervised comments. The baseline use 100D GloVe embeddings to encode text and CNN architecture with 128 filters of size 2, 3 and 4 for each convolution layer, dropout of 0.3 after a flatten layer, two dense layers, categorical cross entropy as the loss function and RMSPROP as optimizer with learning-rate of 0.00005. The baseline model has a final score of 0.8736 on test set. Table 1 shows the sub-metric results of the subgroup homosexual_gay_or_lesbian for comparison with other models.
2. Baseline Model with Augmented Non-toxic dataset
To judge the effects of adding non-toxic dataset into train, I run the baseline with augmented non-toxic dataset mined from Wikipedia articles by Dixon et al., 2018. Note that the dataset contains 5775 non-toxic comments mainly about LGBT groups.
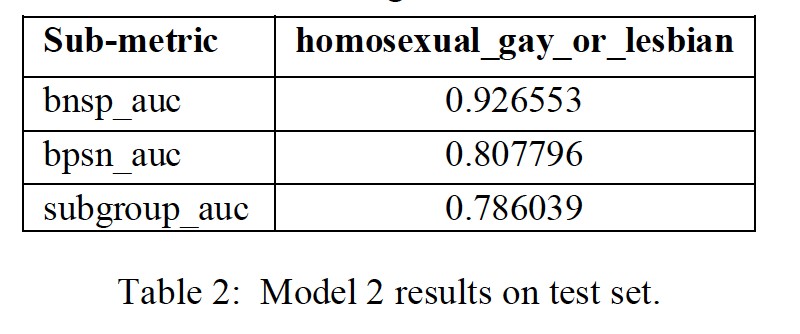
With a slightly more balanced training dataset, the baseline’s final score comes to 0.8755 on test set. It seems like adding non-toxic dataset into train just increase the final metric by a little bit for simple CNN architecture. But it can be seen from Table 2, that at least some bias metrics for LGBT groups have been boosted.
3. Baseline Model with Augmented Non-toxic dataset Bias-mitigated word embeddings
To see the effect of the bias-mitigation method Centroid Embedding as described above, I run the baseline with added non-toxic dataset using bias-mitigated GloVe vectors.

With blurred word vectors for entity groups, the baseline’s final score comes to 0.8723 for test set. See Table 3 for sub metrics results. It is surprised that the bias mitigation method even harms the final score even though that the sub-metric results have shown increase. More future work can be done to investigate the trade-off between one entity group and others.
4. BiLSTM Model with Augmented Non-toxic dataset Bias-mitigated word embeddings
To improve the model performance further, an BiLSTM model with added non-toxic dataset using bias-mitigated word embeddings is trained.
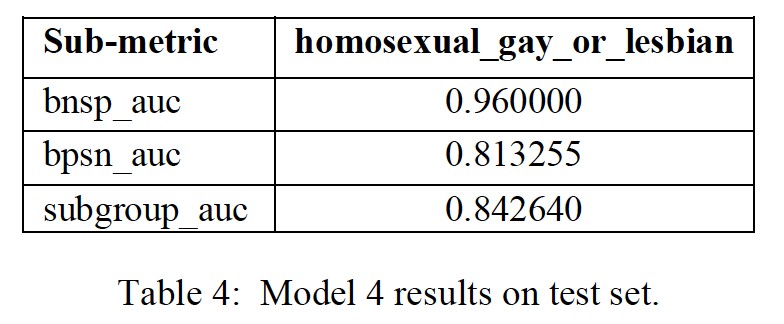
The BiLSTM model uses 200D GloVe embeddings to encode text and dropout of 0.3, two bidirectional LSTM layers, concatenated max-pooling and average-pooling followed by output layer. I use categorical cross entropy as the loss function and RMSPROP as optimizer with learning-rate of 0.00005. The model has a final score of 0.8920 on test set. Table 4 shows the sub-metric results of the subgroup homosexual_gay_or_lesbian for comparison with other models.
Conclusion and Future Work
In conclusion, I evaluate different methods that have proven to be effective to mitigate unintended bias in other cases. However, with the baseline CNN architecture and the train data, I found them not to be as powerful as claimed in other cases. Enhance the modeling architecture and train model with more balanced dataset might be one of the better ways to deal with bias when there are multiple entity groups.
For future work, since it's shown that using Top-5 neighbor to replace the original word is not very useful for bias correction at least for simple CNN architecture models, it's worth trying other methods to mitigate unintended bias. Bias words like “gay” could be replaced with higher-level words in the word net. For example, “gay” could be replaced with “people”. POS tags have also been used to replace sensitive words in practice and proven to be useful in some cases.
BERT has been used in many NLP applications and proven to be very successful, another path is to use BERT to train the toxic comment classification with added non-toxic dataset. Since BERT is a contextualized embedding model, it’s very likely that it can distinguish the entity groups in toxic comments and non-toxic comments and help mitigate the unintended bias.
Reference
[1] Lucas Dixon, John Li, Jeffrey Sorensen, Nithum Thain and LucyVasserman, 2018, Measuring and Mitigating Unintended Bias in Text Classification , https://ai.google/research/pubs/pub46743
[2] Pinkesh Badjatiya, Manish Gupta, Vasudeva Varma, 2019, Stereotypical Bias Removal for Hate Speech Detection Task using Knowledge-based Generalizations, https://www.researchgate.net/publication/3330479
[3] Borkan, Daniel, et al. "Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification." Companion Proceedings of The 2019 World Wide Web Conference. ACM, 2019.
[4] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation.