Introduction
Application fraud costs the financial sector millions each year. It’s important for the credit card companies to catch fraudulent application and accept legitimate customers confidently. In this article, I'll focus on the credit card application fraud detection problem. The goal is to build an effective fraud detection model that has a fine balance. I'll go through feature engineering, feature selection, model building, and evaluation in the following sections.
Dataset
We are given a dataset that contains information of the credit card applicants. The data covers 1 million data records with 9 fields in the year 2016. All the fields in this data set are categorical fields. There is no missing value in the dataset.
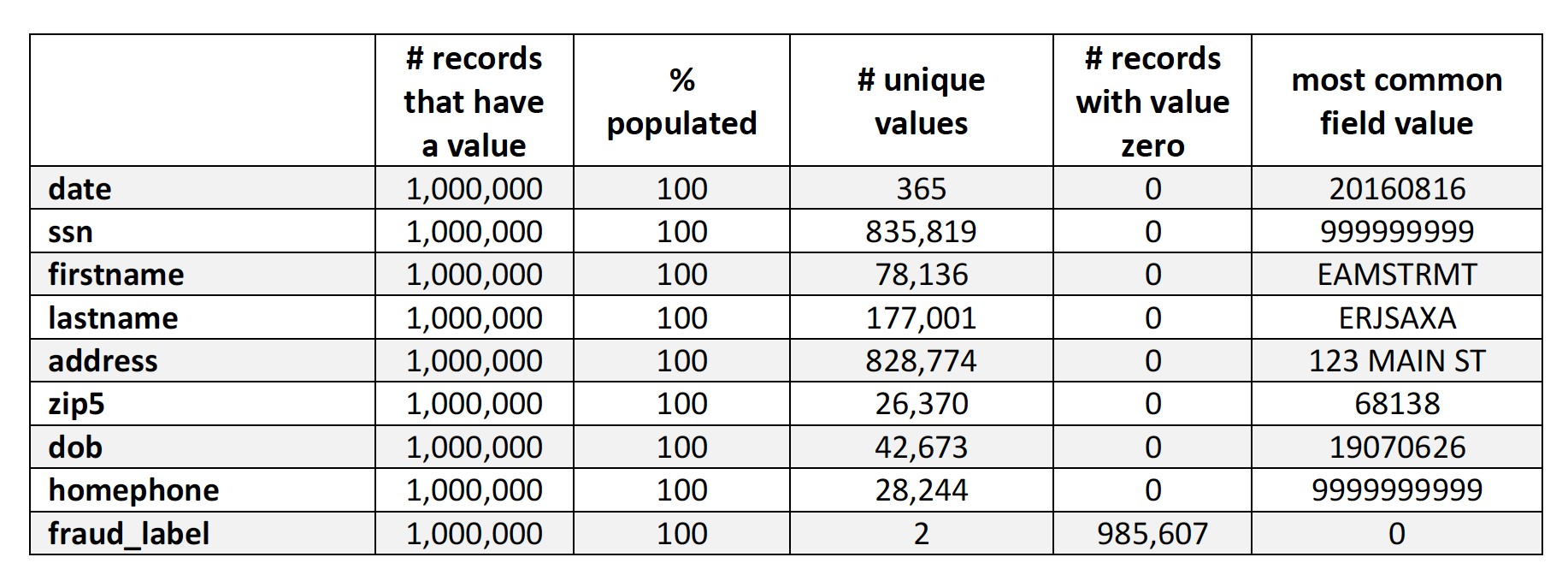
Ten fields are date, ssn, firstname, lastname, address, zipcode, date of birth, phone number, and a fraud label indicating whether this application is fraudulent or not. Among all the applications, about 1.439% of them are fraudulent.
Data Preprocessing
There is no missing value in the dataset so the process of filling in missing value is skipped. However, as shown in the table above, the field “ssn”, “address”, “dob” and “homephone” contain lots of frivolous values like 999999999 for SSN, and 19070626 for Date of Birth. We need to substitute those values with unique indicators because We'll be counting how many times an entity has submitted applicantations in a specified time window, and all these 4 variables will play an important role in entity identifying.
If frivolous values are not substituted, records with these frivolous values will trigger the alarm, even though a large proportion of those records are not fraudulent. How We substitute the frivolous values are described in detail below.
“ssn”: For records with an SSN of 999999999, I'll substitute their SSN with their record number. That way, those records can be separated perfectly. Thus, you’ll see records with SSN of 345, which doesn’t seem like a legal SSN. But I won’t be judging whether an SSN is valid or not in the fraud detection process, so it will be fine.
“address”: There are more than 1,000 records with an address of “123 MAIN STREET”. For those records, their “dob” is substituted with their record number.
“dob”: There are more than 100,000 records with a Date of Birth of “19070626”. For those records, their “dob” is substituted with their record number.
“homephone”: There are more than 50,000 records with a home phone of “9999999999”. For those records, the “homephone” is substituted with their record number. Again, it may seem weird to have an address like “235463”, a date of birth like “5436” and a home phone like “785643”. But this conversion process served the purpose of separating those entities well. Plus, We won’t be judging whether it’s a valid SSN, address, Date of Birth, or home phone in the fraud detection, so it will be fine.
Feature Engineering
We create 2 sets of variables, namely days since last seen variables and velocity variables. Before creating new variables, We created two new fields that combined existing fields to achieve more accurate entity identification:
(1) namedob = firstname_lastname_dob
(2) fulladdress = address_zip5.
On top of that, more combinations were created to link entities:
(1) “ssn+fulladdress”,
(2) “ssn+namedob”,
(3)“ssn+homephone”,
(4)“namedob+homephone”,
(5)“namedob+fulladdress”,
(6)”fulladdress+homephone”,
(7)“firstname+fulladdress”,
(8)“firstname+homephone”,
(9)“firstname+ssn”,
(10)“lastname+fulladdress”,
(11)“lastname+homephone”
(12)“lastname+ssn”.
The reason why we want to use these combination to identify entities is that one variable or two combined variables like “firstname”+“lastname” can not serve as a good identification tool. Lots of people share same first name and last name. Even when two records have the same first name, last name, and same date of birth, it’s still likely that they are not the same person. To achieve better results of identification, these process are necessary.
1. Day Since Last Seen Variables
Days since last seen variables contain important information about the latest occurrence of a certain entity or a combination group. It tells us how many days have passed since I last saw that entity or combination group. It serves as a good indicator for fraudulent application because fraudulent applicants who submitted applicants frequently will have a much lower value for these variables.
We use 18 entity and combination groups to create days since last sen variables. They are respectively “fulladdress”, “namedob”, “homephone”, ”ssn”, “firstname”, “lastname”, “ssn+fulladdress”, “ssn+namedob”, “ssn+homephone”, “namedob+homephone”, “namedob+fulladdress”, ”fulladdress+homephone”, “firstname+fulladdress”, “firstname+homephone”, “firstname+ssn”, “lastname+fulladdress”, “lastname+homephone”, and “lastname+ssn”. For each record, we create a variable that captures the time difference between the actual application date and the date when last time this entity or combination group were seen. In total, 18 days since last seen variables are created.
2. Velocity Variables
In addition to the days since last seen variables, the abnormal frequency of applications might also be an indication of fraud.
For each record, we count the number of applications by each combination group over the past 1 day, 3 days, 7 days, 14 days and 30 days.
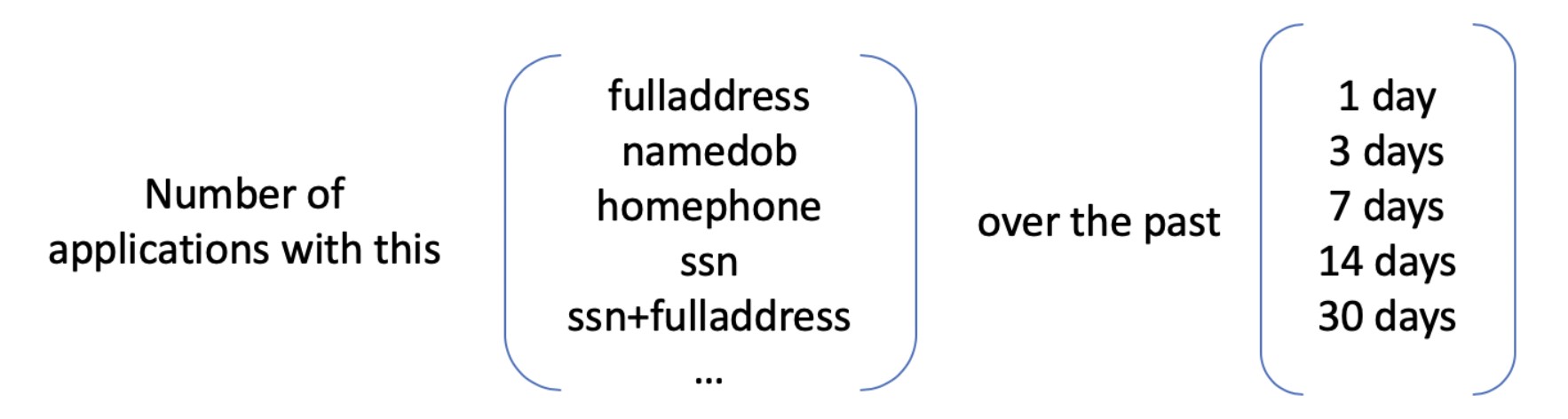
In total, 90 (18 combination groups * 5 time ranges) velocity variables are created. Next, we'll select important features from these 108 created variables.
Feature Selection
We first filter out about half of the variables using two filters KS and FDR, and then use stepwise selection to select 20 variables.
1. Filter 1: Kolmogorov-Smirnov Score
In statistics, the Kolmogorov–Smirnov test is a nonparametric test of the equality of continuous, one-dimensional probability distributions that can be used to compare a sample with a reference probability distribution, or to compare two samples. Here we use KS test to measure the distance between two distributions Pfraud and Pnegative for the same variable. The variable with higher KS score will be the variable that seperates the frauds from non-frauds better.
2. Filter 2: Fraud Detection Rate
Fraud detection rate tells us what % of all the fraud are caught at a particular examination cutoff location. Example: FDR 50% at 5% means the model catches 50% of all the frauds in 5% of the population. FDR is commonly used in business applications. It's more robust and meaningful than the false posotive measure of goodness.
For each variable, we sort all the records in descending order by the variable value. Then, we examine a subpopulation of data by looking at the top 3% records. We count how many frauds are caught in the top 3% data and calculate the percent of frauds caught, which is formulated as the number of frauds caught divided by the total frauds in the whole dataset. A higher FDR indicates that the variable might do a better job in catching the frauds.
3. Backward Selection
KS score and FDR combined help us to filter out about half of the variables. With the left 65 variables, we conduct backward selection using logistic regression. After executing the backward selection algorithm, we get 20 variables that will be fed into the model.
Modeling and Results
We divide the dataset into training, testing, and out of time, which are the special names for training, validation, and testing in the fraud detection field. Then, we built 5 machine learning models to classify the records into fraud or non-fraud. Below is the table that summarizes the performances of 5 ML classifers.
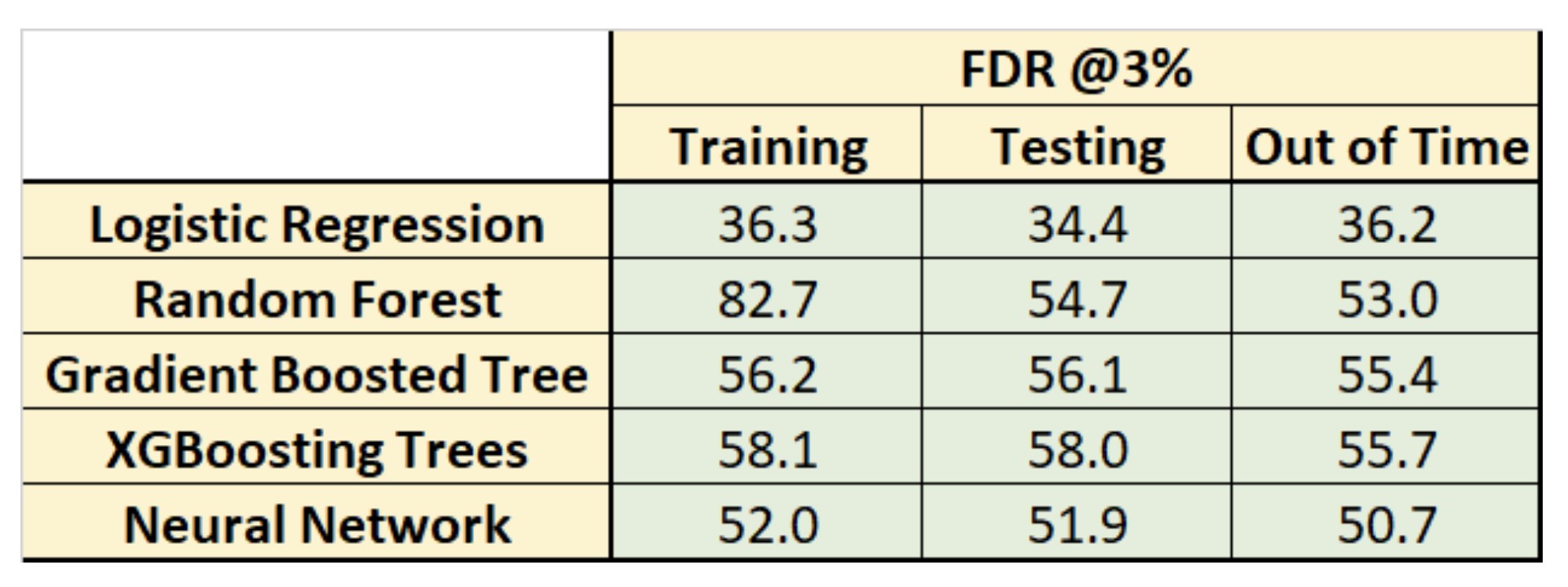
It is clear that XGBoost model performs the best among others since it achieves the highest Fraud Detection Rate in the Out of Time dataset (at 3%). Besides, it does not suffer too much from overfitting like random forest. Its performance on the out of time dataset indicates that it's very likely to generalize well to unseen dataset.
Cost-Benefit Analysis
As mentioned before, it’s important to catch fraudulent application, but it’s also critical that no barriers are put in place that will frustrate legitimate customers wanting to create new accounts. Given an algorithm that outputs probablity of an application being fraudulent, it's up to the bubsiness to decide where the cutoff should be. If the probablity cutoff is too low, then too many applications will be rejected and legitimate customers will be lost; if the probablity cutoff is too high, then many fraud application will be wrongly accpeted and cost the financial institute.
To help the decision maker choose the cutoff point, we plot the cost and benefit graph assuming $2000 gain for every fraud that's caught, and $50 loss for every false positive (non-fraud that's flagged as a fraud).
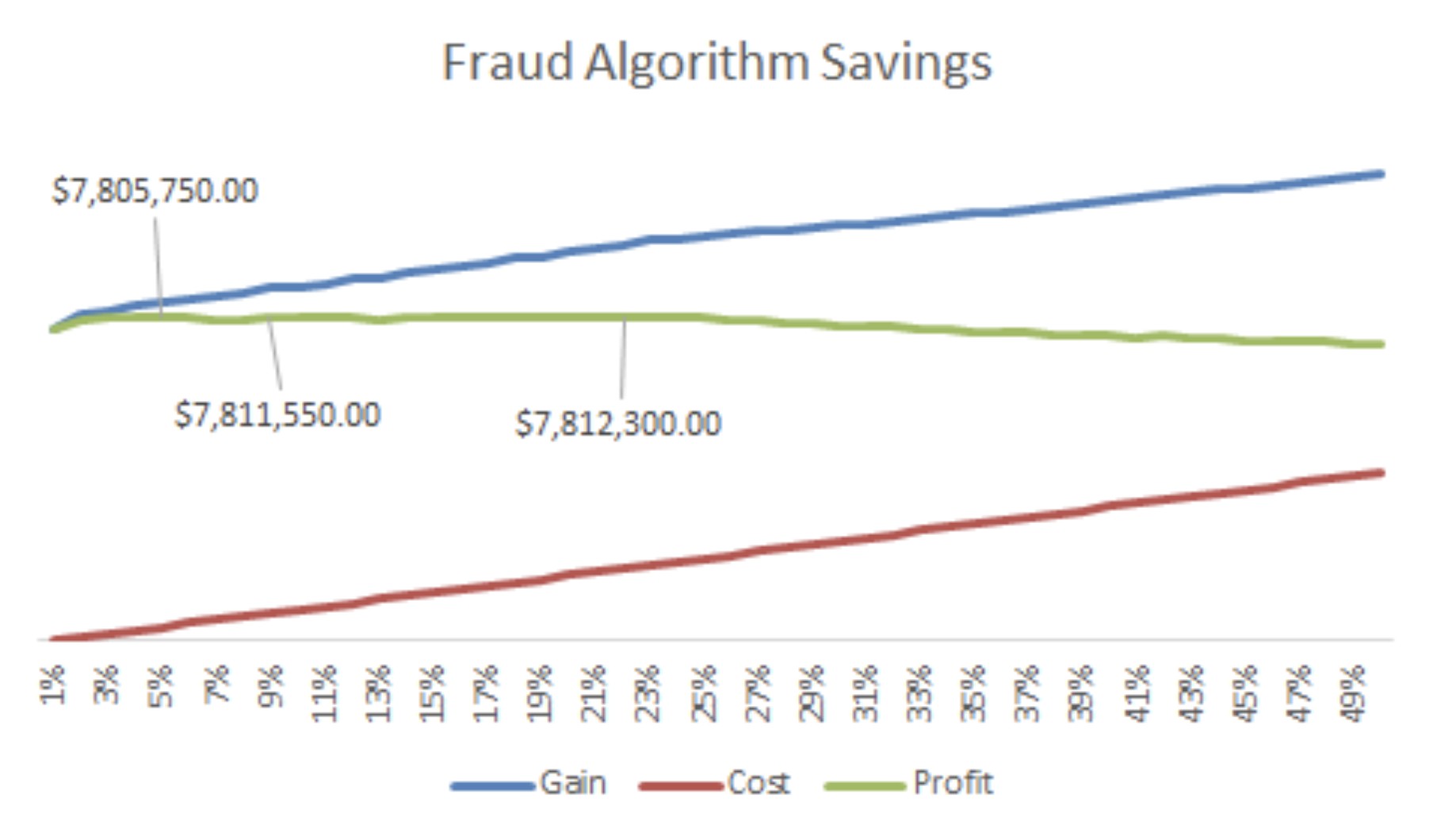
As the graph shown above, from 1% - 50% there are three points where net gain is slightly higher than $7.8 million. They are at 5%, 8% and 22%. We recommend the client to choose the 5% cutoff as that yields similar net gain as the other two with lowest rejection volumn.
Conclusion
In this article, I went through the main steps of building an credit card application fraud detection model. Feature engineering is extremely important for application fruad detection problems as the data available is limited. Entity identifying is the most difficult part in feature engineering and I presented an effective way to help us link entities. With good features, it'll be easier to build a good classifer. In the end, I presented a cost-benefit graph and recommended the cutoff point of rejecting applications.