
The idea of Capsule Networks was first presented by Geoffrey Hinton. This network uses the spatial orientation of the images for its classification task. It provides better results than a conventional CNN.
An adversarial model has the discriminator and generator competing against each other. By implementing the discriminator as a Capsule Network performs better which in turn provides better generator output. The dataset chosen for this project is FHHQ dataset. I used the 128x128 thumbnail images. This dataset consists of 70,000 faces. The images are split into 56,000 training images and 14,000 test images. For evaluating the model FID score was used.
I used DCGAN model as the baseline model. This model was trained for 160 epochs. During training FID score is being calculated over 100 test images after every 2 epochs (1 epoch = 1 pass over the training dataset). The best FID score for DCGAN is 152.85. The FID score calculated over 50,000 test images is 72.34.
DCGAN Results: It is observed that most of the faces are still not properly formed. Some of the faces look realistic but the background is still not being learned.

In a CapsuleGAN, the generator is similar to a DCGAN i.e. a deep CNN. The discriminator of a CapsuleGAN is implemeneted using Capsule layers instead of convolutional layers. During training, the best FID recorded was 126.22. The FID score over 50,000 test images is 31.25. This suggests that the CapsuleGAN is a superior model to than a DCGAN.
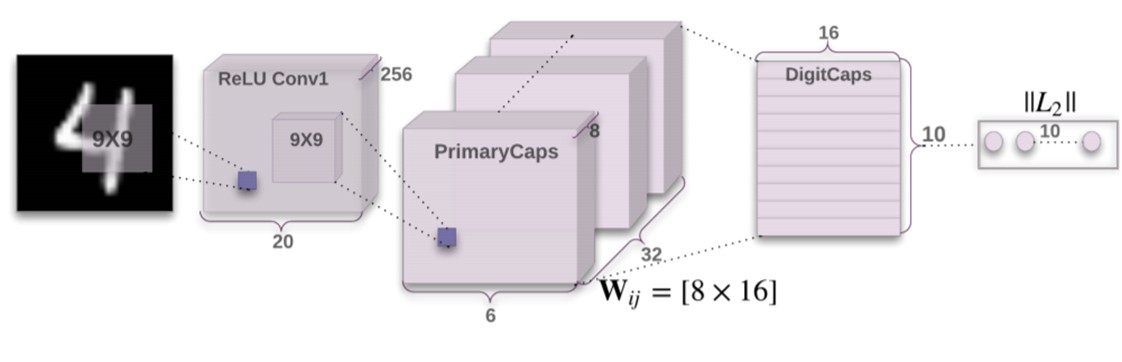
The figure below shows the architecture of Capsule Network which is being implemented in the discriminator. It shows how a MNIST image is converted into capsules. The input for my model is 128x128 image. I have used strided convolutional layers to reduce it to 12x12x256. After this using Reshape layer in keras the primary capsule layer is created which is a 8D vector of size 12x12x32. These 8D vector or capsules now represent different features in the input. This is then passed through a dense layer of 160 nodes where each node is a combination of different capsules from the primary capsule layer. This is then passed to a single node Dense layer which determines if the image provided is real or fake.
CapsuleGAN Results: Some of the results from the CapsuleGAN are shown below. It is observed that in the generated images the structure of the faces are formed much better than the DCGAN. The background is still not formed properly in some of the images. Also, it is noticed that the faces are very diverse. There are men, women as well as children present in these 64 generated images. Also things like spectacles, sunglasses, cap are being generated too.

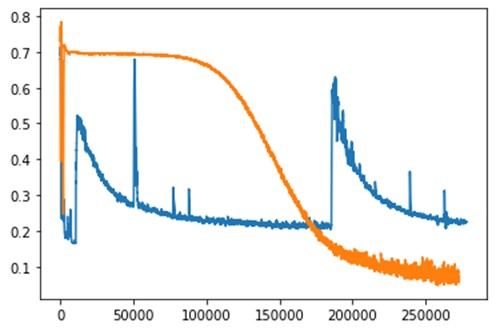
The above image shows the discriminator loss of both models during training. The x-axis shows the number of iterations. The orange color graph is for DCGAN while blue is for CapsuleGAN. The CapsuleGAN learns much faster than a DCGAN and it can be observed from the graph as the loss of CapsuleGAN decreases rapidly till 100,000 iterations. The graph of CapsuleGAN shows an anamoly at around 200,000 iterations when the loss shoots up. This is mostly because of the generator learning some trick to fool the discriminator. The discriminator then starts to learn this trick of the generator and loss starts to decrease.
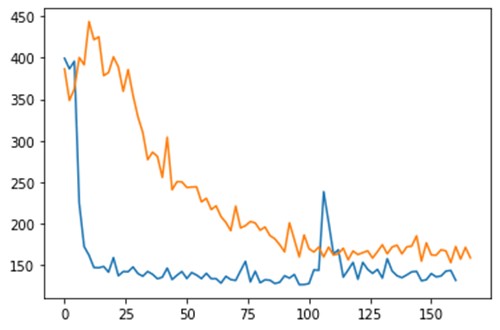
On comparing the FID score during training which is evaluated on 100 test images, it is observed that CapsuleGAN provides low FID score as early as 15th epoch. This low FID score can be credited to the ability of CapsuleGAN to learn the structure of a face from the capsule network. In comparison to a DCGAN, CapsuleGAN provides better FID score as can be seen from the graph.
Link to my repository:- https://github.com/NavedSid/CapsGAN
References:-
https://arxiv.org/pdf/1710.09829.pdf
https://arxiv.org/pdf/1806.03968.pdf










