Summary:
Automatic identification of the semantic content of documents has become increasingly important due to its effectiveness in many tasks, including information retrieval, information filtering, and organization of documents collections in digital libraries. In collections where the documents do not exhibit temporal ordering, investigating a snapshot of the collection is sufficient to gather information about various topics in the collection. It becomes an interesting field to detect trends in the Internet era, where millions of data are posted online every day.
Social media, for example, blogs, forums, and micro-blogs are prevailing, almost all offline events are discussed online. The discussion data, which reflects what people are interested in, is useful for detecting trends.
Usecase: Opioid Crisis; We want to know what is public opinion at the time of an epidemic and how are they changing over the period. Are they getting influenced by any Newspaper or government source?
Consider this use case similar to if an organization is likely to introduce its product in the market. Then the organization should be familiar with what is the public response to a similar product. Are they opinion changing based on advertisements in the newspaper or any other social media source. If they are good at figuring out this then they would be successful to release and market their product.
Problem Statements:
Problem 1: How to get public opinion on the epidemic in a particular time period?
To Analyse public opinion on any epidemic we need to have a source to know what the public is feeling.
Strategy:
Analyzing opioid-related Social Media like Twitter, Reddit communities can bring better insights on how it will affect the quality of life of the public. Therefore, the data streamed from social media such as Twitter, Facebook, or Instagram is so precious to perceive the users' social behavior and his/her opinion. Twitter provides a large scale of text data, which is nothing but public opinions and news. So we can scrap tweets on Opioid during the specific period we want to i.e. from 2010 - 2018.
Problem 2: Classification of Personal and News Tweets
The tweets scrapped may contain Public personal tweets and also news tweets. We want to only analyze how public personal opinion is changing. For that, we need to differentiate public and personal tweets.
Strategy:
For this, we use a clue-based tweet classification. Twitter users tend to specific their personal opinions more casually compared with other documents, like News, online reviews, and article comments. It's expected that the existence of any profanity might cause the conclusion that the tweet could be a Personal tweet. We can count the amount of strongly subjective term, and the number of weakly subjective terms and check for the presence of profanity words in each tweet, and experimented with different thresholds. A tweet is labeled as Personal if its count of subjective words surpasses the chosen threshold; otherwise, it's labeled as a News tweet. We can find the subjective clues from MPQA( Multi-Perspective Question Answering) corpus. According to Xiang Ji and Soon Ae Chun if a tweet has three strong subjective clues and two-week subjective clues then the tweet is marked as Personal tweet else News Tweet.
Problem 3: Detect Topics and their Trend
After collecting tweets from twitter to get opinions of the public from those tweets there is a need to find top topics from the tweets which indeed represents public opinion on Opioid. Topic Detection can be done in different ways, the most familiar method is LDA. But there are not many methods known to find the topic trend along with their sentiment i.e. positive or negative.
Strategy:
KATE is another Neural model that involves an autoencoder, can be used to detect topics from the tweets.
The objective of an autoencoder is to reduce the reconstruction error, and our goal is to extract essential features from data. Compared to image data, textual data is more difficult for autoencoders since it's typically high-dimensional, sparse, and has power-law word distributions. While examining the features extracted by an autoencoder, we observed that they weren't distinct from each other. To overcome this, our approach guides the autoencoder to specialize in essential patterns within the data by adding constraints within the training phase via mutual competition. In competitive learning, neurons compete for the proper to retort to a subset of the input file, and as a result, the specialization of every neuron within the network is increased. Note that the specialty of neurons is what we wish for an autoencoder, mainly when applied to textual data. By introducing competition into an autoencoder, we expect each neuron within the hidden layer to recognize different patterns within the input file.
As we have time-series data i.e. we have data from 2010 to 2018, We can apply this method each year individually while setting the same hyperparameter required by the model. KATE produces topics from tweets and assigns each topic a number, which decides the probability of the topic being spoken. Using those topics and the probability we can visualize the topics/ Concerns of the public at the time of opioid. To know the opinion related to that concern we can apply sentiment analysis. Below is the visualization which says the concerns of the public during an opioid and the opinion related to that concern.
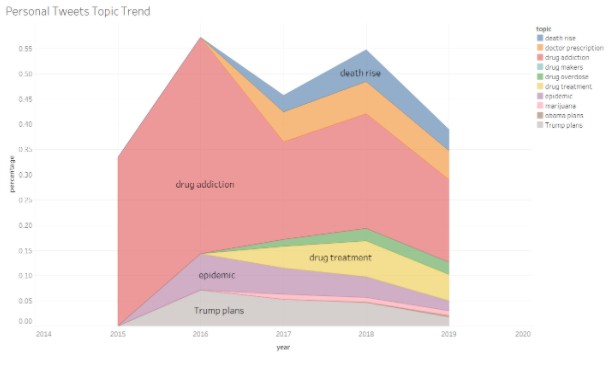
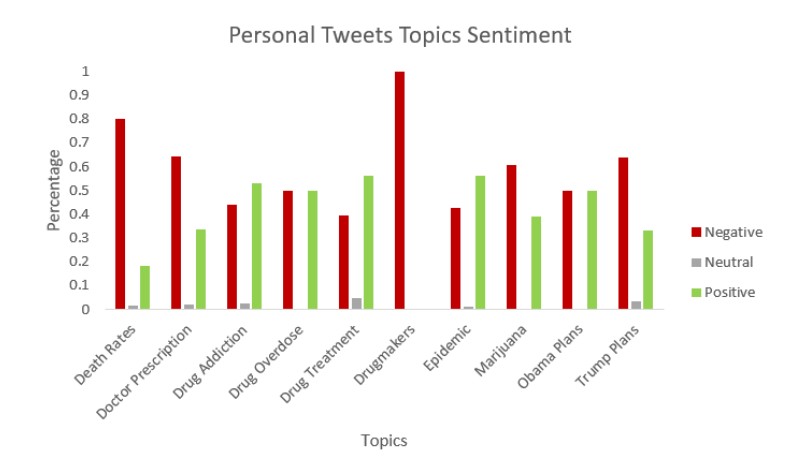
We can repeat the same process with Newspaper data to know what news media is trying to project at the time of the opioid crisis.
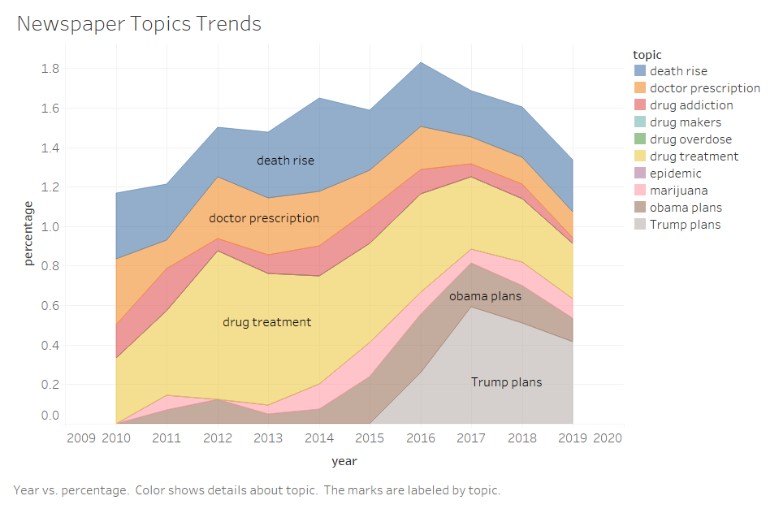
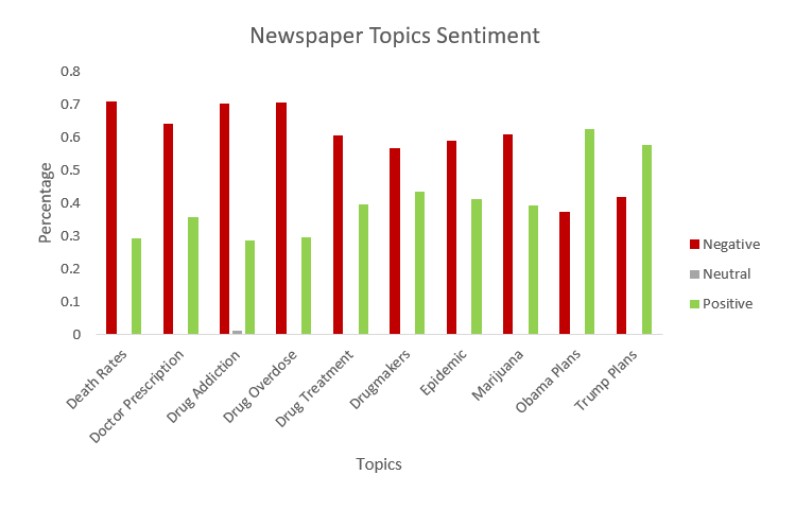
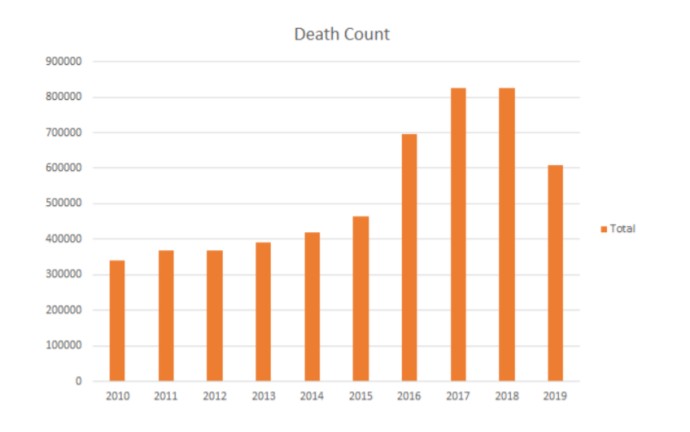
From the above graphs, we see that though the deaths are increasing due to opioids, Newspapers are trying to maintain a positive environment. And they are also trying to project Trump plans towards opioids are effective.
Problem 4: Genuineness of the data
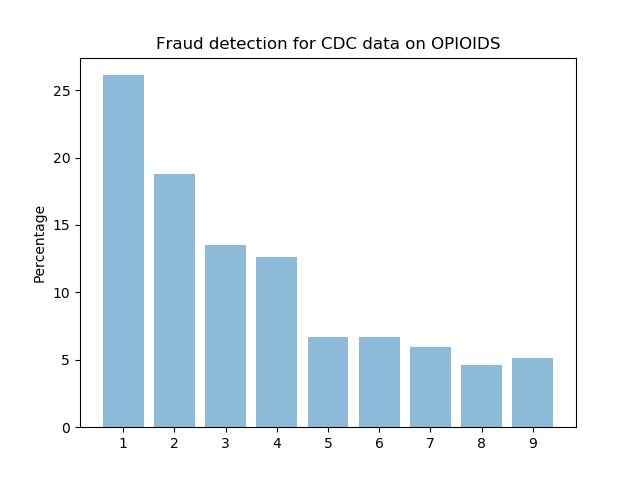
We can also deaths due to opioids in the period from the CDC(Center for Disease Control). But there was a change in government in 2016. Republican party tried to project wrong hope in public by advertising that the deaths due to opioids are being decreased. New York Times published an article telling us that the government is bringing false hope. So there was a need to evaluate whether the data provided by the CDC is correct or not.
Strategy:
I remember studying Benford's law during my data structures course. Benford's law also called the Newcomb–Benford law, the law of anomalous numbers, or the first-digit law, is an observation about the frequency distribution of leading digits in many real-life sets of numerical data. The law states that in many naturally occurring collections of numbers, the leading Significant digit is likely to be small. For example, in sets that obey the law, the number 1 appears as the leading significant digit about 30% of the time, while 9 appears as the leading significant digit less than 5% of the time. Using this law we can find whether the data is fraud or not. Interestingly, the results were satisfying.
Conclusion:
In Conclusion, I would like to say that there is a need for a framework which can be able to detect public opinion and their trend which will be helpful for many organizations and also for the government to make plans or schemes based on public opinion.