What is a Data Lake?

A Data Lake is a new form of data-warehouse that supports a variety of data formats structuring, data exploration activities, machine learning, graph analytics, and recommendation systems. Traditional data-warehouses do not provide many facilities for unstructured data, hence data lakes are used.
Storage and management of Data Lakes
A data lake is a repository where data is stored in the raw format, especially object blob files. A data lake can be established either on-premises, which requires a lot of hardware costs or can be deployed on the cloud (Amazon AWS, Google Cloud, Microsoft Azure, etc.). Most of the organizations prefer cloud technology for data lakes because of many readily available tools, less maintenance, and pay-as-you-go.
However, improper management of data lakes can be disastrous. This can lead to the creation of “Data Swamps”. A data swamp is a deteriorated and unmanaged data lake that is either inaccessible to its intended users or is providing little value.
Comparison between Data-warehouse and Data Lakes

Implementation (on the cloud)
There are several ways to implement a data lake on cloud-based on cloud vendor and its internal services. Here, I would be providing some of the implementation design on Amazon AWS.
- AWS EMR (HDFS + Spark)

This the simplest design where data is transferred from source to the Amazon EMR and later this transformed data is accessed by the BI Analytics app. The source of this design can include but not limited to Amazon S3, AWS RDS, Cassandra, DynamoDB, and EC2. The intermediate stage which includes Amazon EMR (Elastic MapReduce) consists of HDFS and Spark.
EMR cluster is created once, but it can grow and is not supposed to be shutdown. The inclusion of HDFS makes this design a little complex and difficult to manage.
2. AWS EMR (S3 + Spark)
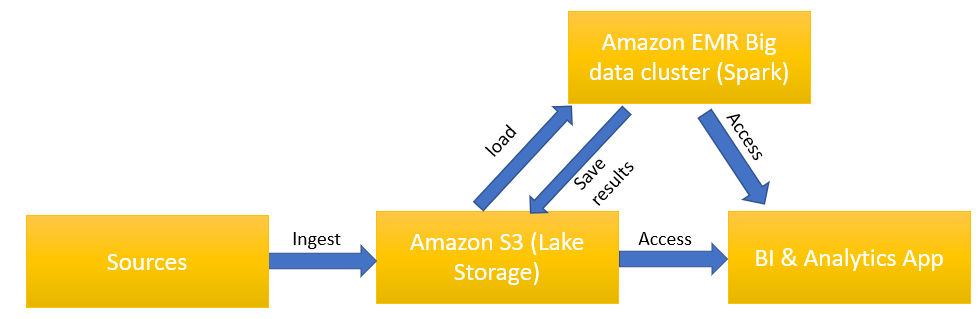
In this design approach, no HDFS is involved and all data is stored on S3 buckets. Data is loaded to EMR for processing and later query/processing results are stored back into S3. The EMR cluster is spun on-demand and remains shut down otherwise. This approach has several advantages over previously mentioned design, such as less costly, easier to manage, and high performance.
3. AWS Athena (FaaS)
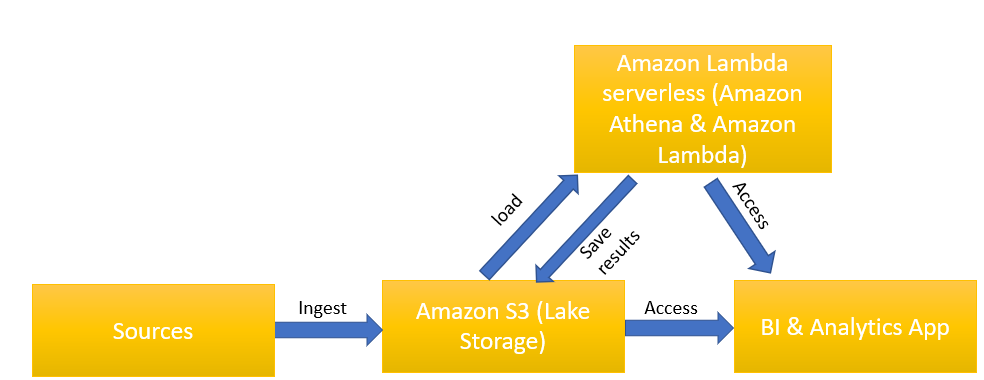
Function as a service (FaaS) is a category of cloud computing services that provides a platform allowing customers to develop, run, and manage application functionalities without the complexity of building and maintaining the infrastructure typically associated with developing and launching an app.
In the above design, all data is stored on S3. Athena is a service that can load process data on Serverless Lambda resources (pay by execution time, not by machine up-time).