
- INTRODUCTION
Disneyland Paris, originally Euro Disney Resort, is an entertainment resort in a new town located 32 km (20 mi) east of the Centre of Paris. It is the most visited theme park in Europe. Disneyland Paris celebrated its 25th anniversary in 2017. In 25 years, 320 million people have visited the park. Naturally, it is hard to expect reviews from each and every visitor and also hard to consider the reviews fetched over a period of 25 years as many things might have changed over the period of time. Hence, we considered the last 5 years of reviews which are fairly more recent and would more likely align with the current developments in the park.
This project mainly aims to let the Disneyland’s management to know the overall view of the visitors about the park and help them to fix any unknown or unnoticed issues which are feasible for them and also help them to improve the visitor’s liking which may persuade the visitors to visit the park more frequently.
In customer-based industries, it is highly important for the management to consider the reviewers remarks and act as per their feasibility so that the customers stay loyal to the industry, in this case the park, and persuade them to visit the park and foresee their suggestions put to implementation which would build a sense of satisfaction and also trust among the visitor’s.
- PROJECT DESIGN
The Facebook reviews are mined using these text mining methods - sentiment analysis, text classification, and topic modelling to review the ratings, visualization of positive and negative reviews over a period of 5 years (2012-2017). Word cloud is also used to determine the frequency of words used in the reviews and to measure the positivity and negativity of those reviews.
III. IMPLEMENTATION OF THE PROJECT
The data found in Kaggle.com had the following columns:
- UserID
- Review
- Stars
- Date_format
- Time_of_day
- Hour_of_day
- Day_of_week
- Review_format
- Review_lang
- Month_year
- Review_len
- Review_nb_words
The columns which were used are:
- Review_lang
- Stars
- Review_format
- Review_len
- Review_nb_words
A total of 2394 English reviews are considered.
3.1. Sentiment Analysis
Sentimental analysis of each of the reviews given in English language determine their polarity and subjectivity using Text Blob NLTK Package. Polarity is between -1 and 1 which determines positive and negative aspect of those reviews. Subjectivity is between 0 and 1 with 0 being objective and 1 being subjective. Accuracy of the positive and negative sentiment of those reviews are calculated. NumPy method is used to help us with different combinations of subjectivity/polarity.
3.2. Text Classification
In this method, a list of all the words in review column is created and then the most frequent words used in all reviews are checked. Feature extractor is defined to create a feature set through which the training and accuracy of those reviews are calculated. Text classification also helps with error analysis on those reviews.
3.3. Topic Modeling
Topic Modeling was performed on our dataset using genism package to see most significant topics and the most important words in those topics. Topic modelling also helped us in knowing the probability for each word in each topic.
- DATA ANALYSIS AND INFERENCE
TABLE 1 – SUMMARY OF NUMERIC COLUMNS OF DATASET
Statistic Summary | review_len | review_nb_words | stars |
Mean | 224.98 | 41.79 | 4.32 |
Standard Error | 5.8 | 1.093 | 0.025 |
Median | 122 | 22 | 5 |
Mode | 41 | 11 | 5 |
Standard Deviation | 283.82 | 53.5 | 1.26 |
Sample Variance | 80556.82 | 2863.02 | 1.61 |
Range | 2912 | 564 | 4 |
Minimum | 3 | 1 | 1 |
Maximum | 2915 | 565 | 5 |
Sum | 538605 | 100061 | 10366 |
Count | 2394 | 2394 | 2394 |
Number of positive reviews – 1952 out of 2394 English reviews
Number of negative reviews – 206 out of 2394 English reviews
FIGURE 1 – WORD CLOUD AFTER REMOVING STOPWORDS,
PUNCTUATIONS, AND STEMMING

FIGURE 2 – AVERAGE NUMBER OF WORDS IN REVIEW
COMMENTS V/S STAR RATING
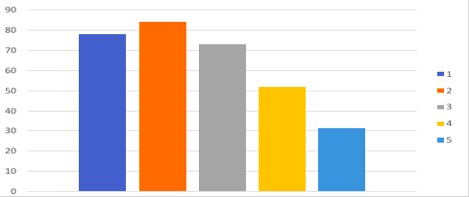
FIGURE 3 – STAR RATINGS
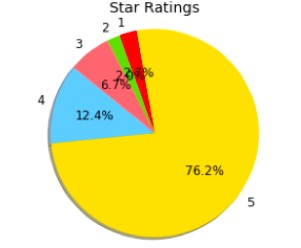
FIGURE 4
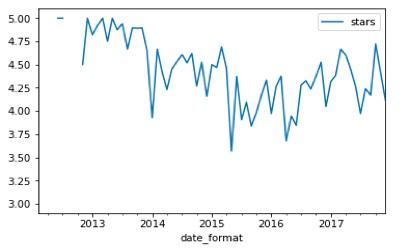
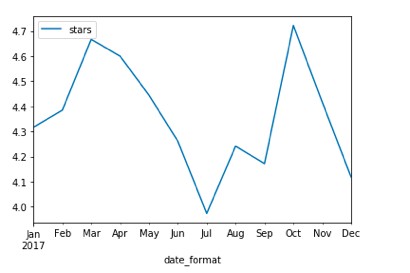
FIGURE 5
- RESULTS AND DISCUSSION
5.1. Output from Sentimental Analysis:
- Positive reviews(stars=3)
- Negative Reviews(stars=2)
- Number of Positive Reviews: 2093
- Number of Negative Reviews: 301
- Accuracy of Positive Reviews: 87.72%
- Accuracy of Negative Reviews: 60.46%
5.2. Output from Text classification
Accuracy: 86.43%
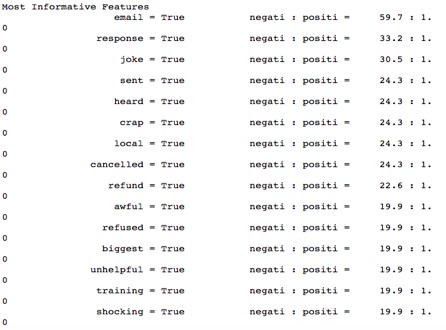
TOPIC MODELING- LDA
Topic modeling is a type of statistical modeling for discovering the abstract “topics” that occur in a collection of documents. Latent Dirichlet Allocation(LDA) is an example of topic model and is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions.
We have divided all English text reviews into 2 parts: Positive reviews corpus and negative reviews corpus.
First, we are running Topic modeling-LDA on cleaned positive reviews corpus. Train our lda model using gensim.models.LdaMulticore and save it to ‘ldamodel. In below code we are taking num_topics = 4, because we want 4 main clusters/topic from positive review corpus. Passes= 1000 means that the model will rum for 1000 iterations and then final result will be displayed.
ldamodel = Lda(doc_term_matrix, num_topics= 4, id2word = dictionary, passes= 1000)
Now, we are printing the results:
print(ldamodel.print_topics(num_topics=4, num_words=5))
Results from model are below:
- 021*"hotel" + 0.019*"amaz" + 0.019*"love" + 0.017*"stay"
- 032*"time" + 0.027*"christma" + 0.021*"show" + 0.017*"alway" + 0.016*"parad"
- 013*"charact" + 0.010*"ride" + 0.009*"favourit" + 0.009*"world" + 0.009*"enjoy"
- 033*"fun" + 0.033*"experi" + 0.027*"adult" + 0.026*"awesom" + 0.023*"top" + 0.021*"everyon" + 0.015*"kid"
From above clusters, we can infer that below are the top 4 things which most of the visitors loved:
- Visitor's found Disney's Hotel Stay Amazing
- Christmas Day Parade and show were liked by many
- Disney Characters and Rides were great
- Fun experience for kids as well as for adults
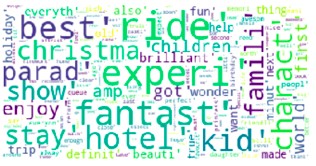
The word Cloud of positive corpus is below:
Next, we are running Topic modeling-LDA on cleaned negative reviews corpus. Train our lda model using gensim.models.Lda and save it to ‘ldamodel. In below code we are taking num_topics = 4, because we want 4 main clusters/topic from negatie review corpus. Passes= 1000 means that the model will rum for 1000 iterations and then final result will be displayed.
ldamodel = Lda(doc_term_matrix, num_topics= 4, id2word = dictionary, passes= 1000)
Now, we are printing the results:
print(ldamodel.print_topics(num_topics=4, num_words=5))
Results from model are below:
- '0.014*"time" + 0.012*"realli" + 0.011*"queue" + 0.010*"span"
- '0.016*"smoke" + 0.015*"even" + 0.013*"ride" + 0.013*"paris" + 0.012*"peopl
- '0.021*"staff" + 0.016*"time" + 0.012*"rude"
- 0.008*"food" + 0.007*"time" + 0.007*"onli" + 0.006*"need"
From above clusters, we can infer that below are the top 4 things which most of the visitors loved:
- Long waiting time in the queue
- People have issues with co-visitors smoking within the park premises
- Rude Staff
- Complains about Food
The word Cloud of negative corpus is below:

References
1) Electronic Media
Dataset:
https://www.kaggle.com/romain9292/disneyland-paris-facebook-reviews
2) Books
Natural Language Processing with Python by Steven Bird, Ewan Klein, and Edward Loper
Speech and Language Processing by Daniel Jurafsky Stanford University, James H. Martin University of Colorado at Boulder










