Summary
Data preprocessing is a fundamental process in the field of data analytics. The aim of data preprocessing is to shape the data as per the requirements ensuring that it is accurate, clean and consistent. There can be several techniques used for data preprocessing depending on the use case. This article majorly describes my own experience with data preprocessing, specifically for getting a dataset ready for time series analysis. It entails the challenges faced by the team in handling the raw datasets and the techniques we used to solve those challenges. After preprocessing the data, we built a time series predictive model to forecast mortality rate for different countries using the WHO Mortality Dataset.
1. Theory
As we know, data analytics is used to analyze raw and unstructured data to gain actionable insights for optimizing processes in order to increase the overall efficiency of a business or a system. It also includes the use of machine learning algorithms and predictive modeling techniques to get an insight into the foreseeable future.
However, there is one important aspect of data analytics which is the most time consuming; Data Pre-processing. According to a Forbes article, it was reported that scientists spend almost 70%-80% of their time in data preprocessing. This translates to spending almost 6-7 hours of the 8 hours of a normal working day on data preprocessing. This is also one of the least enjoyable parts of analytics but one of the most critical components in the early stages of performing analysis on datasets. Another study conducted by Forbes revealed that about 75% of scientists find data preprocessing as the least enjoyable part of their work. These studies indicate that although data preprocessing is a monotonous task, it is an essential and a fundamental step when performing analysis on data.
1.1 What is Data Preprocessing?
Data pre-processing generally is a process comprising to techniques to clean, organize and transform data in such a way that it is ready to be analyzed i.e. it can be interpreted by the software or the piece of code which we use to perform analysis on the data. It is essentially filtering huge chunks of structured/unstructured and raw data from various sources as per the business requirements. Data preprocessing is needed to comply with data quality standards such as:
- Accuracy: Accuracy is one of the major components when assessing the quality of data. Dealing with inaccurate data is one of the major points as the analysis of such datasets yield faulty results which leads to incorrect decision-making.
- Completeness: Dealing with incomplete data is one of the major challenges that data analysts face daily which may include lacking attribute/feature values of interest. Analysis of incomplete data may cause a bias in the estimation of parameters thus giving inaccurate results.
- Consistency: Working with inconsistent data hampers the progress of our analysis and often, these inconsistencies are difficult to spot as well. Aggregation of inconsistent data leads to confusion and causes several errors in performing analysis of the data. For example, different formats of dates and times in different countries often cause an issue while merging two or more datasets. Analyzing inconsistent data will not only give incorrect results but also lead to decreased performance of the business process.
These 3 are the major factors which need to be taken care of in order to perform high-quality analysis on the data and obtain precise results to optimize business processes.
1.2 Four major steps involved in data pre-processing
- Data Cleaning: Data cleaning often includes techniques to clean and filter bad data by removing outliers, replacing missing values, correcting inconsistent data, smoothing noisy data etc. This step ensures that the data is organized as per the format required by the company, thus making it easy to conduct analysis on the data. The techniques generally used for data cleaning are; removing irrelevant values, eliminating duplicate values, converting data types of the attributes and filling in missing values. There are several other techniques which can be used and their application depends on the use-case.
- Data Integration: Data integration basically refers to the consolidation of data from various sources into a single dataset. This could lead to redundancy and inconsistency in the dataset thereby affecting the performance of our model. The most common techniques used for data integration are as follows:
- Data Consolidation: The data is physically merged together at a single location. Example: storing data in a data warehouse.
- Data Propagation: The data is typically copied from one location to another and it is synchronous or asynchronous.
- Data Virtualization: This includes an interface which is developed to provide a real-time and unified view of data from multiple sources. Example: Denodo is one such tool that allows data virtualization
- Data Reduction: Data reduction helps to condense the volume of large datasets into smaller fragments as per the requirements. This helps in faster and efficient processing of data reducing thus reducing the amount of time and giving us similar results. It basically allows us to filter a large dataset and use it as per the analysis we want to conduct. For example, using a minimum threshold value to remove attributes that have a value below the threshold.
- Data Transformation: This is generally the final stage in data preprocessing. It involves converting data from one format or structure to another format or structure, as per the user requirements. It helps us make the data ready for analysis and data modeling. Example, adding new attributes to the dataset which may be useful for analysis, normalization of datasets etc.
There are other multiple approaches to preprocessing data and it still attracts scientist for research development in this field because of the sheer volume of raw and unstructured data produced each day. Data preprocessing is a fundamental step in performing analysis on data and it should be performed with utmost precision.
2. Personal Experience in Data Preprocessing
I have recently completed my master’s degree in Information Management from the University of Illinois at Urbana Champaign. My specialization is in Data Analytics and Business Intelligence. I have got my hands dirty working with all different types of datasets used for conducting analysis in several projects. I will describe one such experience in detail below.
2.1 WHO Mortality Dataset Analysi
2.1.1 Introduction
The primary goal of the research project was to analyze the WHO/PAHO global diseases dataset and build a time series predictive model to forecast the mortality rate of any given disease in the dataset. In this project specifically, we decided to focus on the mortality rate for the two acute lower respiratory diseases; Bronchitis and Tuberculosis. The main regions of our focus were the Americas.
The 3 major research questions/hypothesis which we wanted to answer were:
- Which attributes influence the death rate for each country?
- Is it viable to build a time series predictive model for the available dataset?
- What are some other indicators we need to build and improve the accuracy of the model?
2.1.2 Datasets
There were primarily two datasets which were used for conducting the analysis
1) WHO Mortality Dataset
This dataset was obtained from the WHO website, which, as we know outlines information about health situations and trends globally. The dataset consists of records or observations of deaths with regards to a disease which can be identified by the ICD10 column. It’s shown in the figure below:
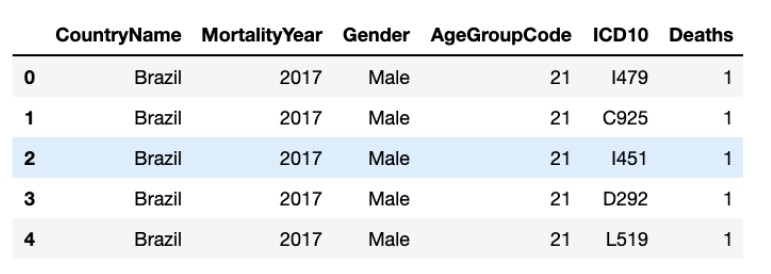
The columns we will use in the analysis are:
- CountryName - the name of the country
- MortalityYear - the year when the observation was recorded for
- ICD10 - the column that will help in identifying the type of disease
- Deaths - the total number of deaths for that particular disease in that particular year
2) World Bank Dataset
This dataset was collected from the Data World bank website, which basically has information about the different indicators we will be using to add more information to the already existing PAHO Mortality dataset. Each observation in this dataset consists of data with regards to a country and its associated statistics. A snapshot has been attached below:
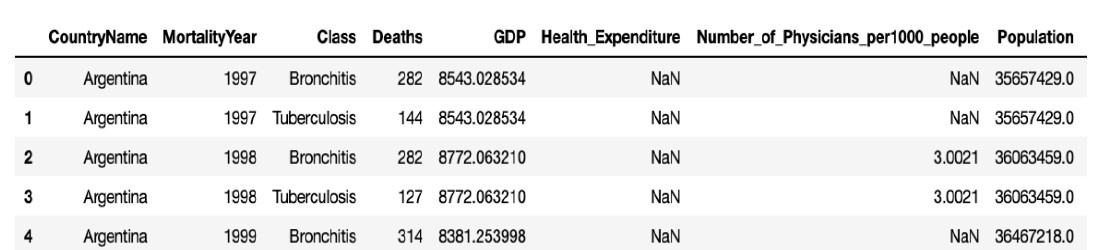
The columns we will use in the analysis are:
- CountryName - the name of the country
- MortalityYear - the year when the observation was recorded for
- Class - whether it is Bronchitis or Tuberculosis
- Deaths - total number of deaths observed
- GDP - Gross Domestic product value for a country
- Health_Expenditure - the amount of money spent on health on an average
- Number_of_Physicians_per1000_people - the total number of physicians per 1000 people observed in the country
- Population - the population of the country
2.1.3 Data Problems and Preprocessing
The datasets that were collected had multiple problems pertaining to their use for a time series model. In both the datasets, some of the problems that we observed were missing data, limited data points and inconsistency in naming. Each of these problems is discussed in detail below, along with them are steps which were executed to clean up the dataset.
1) Data Inconsistency
There was inconsistency in how the countries were named in PAHO Mortality and World Bank datasets. There was no other simpler method than to list all the unique names of the countries between the datasets and perform set operation to identify the differences. Once we had the inconsistent names, we manually named the countries with the same spelling and capitalization in both the datasets. The reason this step was important for data cleaning was because of the merge that needed to be done once the datasets were cleaned.
2) Limited Data Points
In the PAHO Mortality dataset, it was observed that there were countries that had no data points for a few ICD codes. This could be either because the countries did not report any deaths for these ICDs or there were no deaths observed at all. This made is challenging for us to build a time series model as limited data points would not yield accurate results. Hence, we decided to focus our predictive model to those countries which had data available across the entire time frame from 1995 – 2017. These countries were – United States, Canada, Brazil, Colombia, Argentina, Ecuador, Peru, Mexico, Cuba and Puerto Rico.
3) Missing Data Points
For the World Bank dataset, we observed that there were few missing values or NaN (Not a Number) values i.e. non-numerical values in fields where a numerical value is expected. This would become a problem when we are training a time series model. For this, we simply used a neural network method for data imputation called the MICE method. This type of imputation works by filling the missing data multiple times. Multiple Imputations are much better than a single imputation as it measures the uncertainty of the missing values in a better way. The MICE method is a more intelligent alternative as supposed to simply filling the missing data with mean, backwards or forward fill.
The dataset before preprocessing looked like:
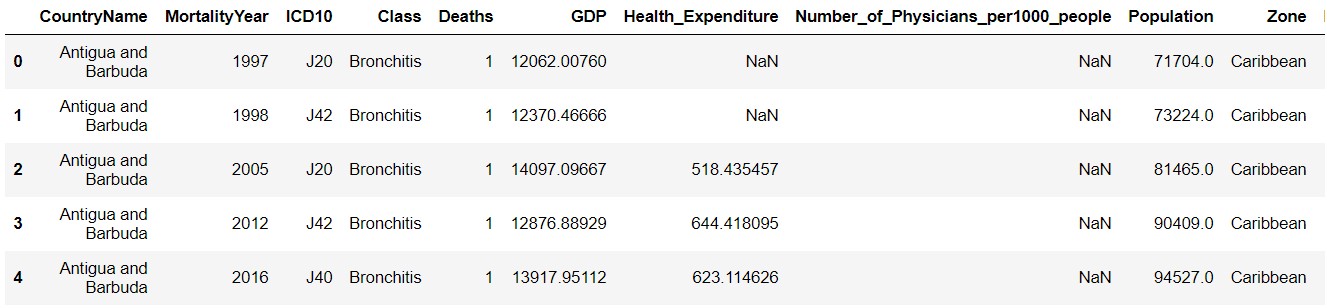
The dataset after preprocessing looked like:
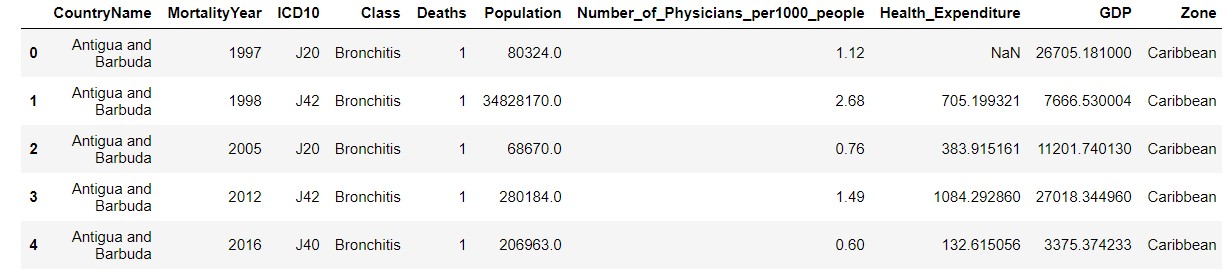
Major Data Transformations performed:
1) Added a column indicating deaths per 100000 people for a country rather than showing individual death count
2) Added indicators Population, Number of Physicians per 1000 people, Health Expenditure and GDP to build a predictive model
3) Divided the countries into various zones as indicated in the snapshot. Example, Caribbean
4) Consolidated the World Bank dataset and WHO Mortality dataset into a single dataset using left inner join
5) Removed unwanted rows by filtering the dataset depicting mortality rate of the top10 countries as stated above
2.1.4 Methodology
For the first research question, the extent of influence of the indicators on death rate was done using simple python libraries such as plotly and bokeh. Using these libraries bar charts, scatter plots and line charts were illustrated in order to check and assess the influence of indicator data on the death rate count. All these graphs were displayed in a jupyter notebook which helped in quick feedback and reusable code.
For the second research question, the validity of building a time series model for the provided dataset. Here we used ARIMA and ‘auto_arima’ models available in the ‘statsmodel’ and ‘pmdarima’ libraries in python. The ARIMA model or also known as Autoregressive Integrated Moving Average best works with time-series data that exhibit no seasonality. This type of model captures a suite of different standard temporal structures in a time series. Which thereby ends up providing us with a strong prediction tool which can forecast how the time series would look like in the future. The model considers all the patterns which end up being a tool to even flag anomalies. To assess the performance of the model residual, mean square error along with AIC value were used as evaluation metrics. Plotting the residual mean square error is also another way to assess if the model is predicting efficiently. At the same time auto_arima model, a stepwise model that checked if the parameters we provided to the function that is the p, q and d values were tuned to be the best performant. This function helps in reinforcing the ARIMA model that was built.
The last research question, to build a machine learning model that can include the indicators for predicting the time series nature of the death rate count. Here we used a VAR model also known as Vector Autoregressive model in order to train the time series. At its core, the VAR model performs univariate regression time series modeling. It tries to predict multiple time series variables using the same model. This model will be used to not only train and test the time series data that is available but will also try to forecast the data into the future. The metrics to evaluate VAR model will be Mean absolute percentage error along with AIC and root mean square error. If these values are low it indicates higher accuracy of the prediction model.
Vector Auto-Regression Model
The dataset was divided according to country and the class of disease and a model was created for each of these divisions. Totally, there were ten models which predicted the death count from Bronchitis in all the ten countries and there were ten more models that predicted the death count from Tuberculosis. While building the model, three columns ‘Country Name’, ‘Class’ and ‘Zone’ were dropped as there was a model for each country. One-step ahead forecasting was conducted to check how the model performs. This helps us to evaluate the accuracy of the model as we already know the values but are still predicting. For each country, the data was present for twenty years (1997 to 2017). So, in order to evaluate the model, the first seventeen years (1997 to 2013) were considered as a training set and the model was trained. The death count for the years 2014 to 2017 was forecasted and compared with the actual values. The country Argentina was chosen as the sample to plot the intermediate results.
The final dataset obtained after processing and cleaning was a Non-Stationary dataset and hence the order of differencing was calculated. Augmented Dickey-Fuller Test (ADF Test) was performed to calculate the order of differencing. For each country-case model, the function would check if the time-series is stationary or not and if it is not, it dynamically calculates the order using the ADF test. Once the order of differencing is calculated, the time-series dataset is differenced using the pandas inbuilt method df.diff().
Further to check the closeness of the variables, a Cointegration Test was conducted. Cointegration test helps to establish the presence of a statistically significant connection between two or more time-series variables. It was observed that the population is not required in the prediction of the death count.
Once the model was fit with data, Forecast Error Variance Decomposition (FEVD) was plotted. It indicates the amount of information each variable contributes to the other variables in the autoregression.
The model was used to make predictions and the results were generated, but this result is right now in a second differenced form. In order to invert the differencing operation, a function ‘invert transformation’ was created. This function takes the differenced data frame and inverts the results to get the forecast for the original scale.
2.1.5 Results
The Mean Absolute Percentage Error (MAPE) of the VAR predictive model forecast was 8.22%. The Root Mean Squared Error (RMSE) was 17.7671 and the Akaike information criterion (AIC) of the model was 50.07.
Using the same functions, country-specific models were created for both the diseases and plotted on an interactive graph. Here, the model was trained for the years 1997 to 2017 and the death count was predicted until the year 2020.
2.1.6 Future Scope
Our findings and research have a scope limited to only Tuberculosis and Bronchitis with a limited number of indicators used to build the time series prediction model. One way to carry this research further would be to investigate other indicators like the number of hospitals in the country and insurance data to get a deeper look at the history of the diseases. This could also be broadened to include other diseases as well.
This lays the foundation for future research where a more comprehensive data, for example, monthly data for the deaths caused by these two diseases worldwide would be better to build a more accurate and robust predictive model. The focus area of this research can be expanded to include all the diseases in the PAHO mortality dataset and build a similar time series model to predict the death count for all the diseases. It can also be carried out on a global basis to include as many countries affected by deaths caused due to these two diseases.
3. Conclusion Learnings
Data preprocessing is indeed a very important step in data analytics, and it should be performed with due deliberation to achieve the best possible results. The techniques used for data preprocessing can vary according to each use case and requirements hence it is very essential for a data analyst to understand the nature and the type of data. A little mistake can lead to results which are way off than the desired accuracy and could lead to a loss for the company as well. The research in the field of analytics is progressing with each passing day, hence the scope of discovering more efficient methods for data preprocessing is vast.
My key takeaway after performing hands-on data preprocessing is that no matter the industry and the nature of data, preprocessing is a very essential step because the real-world data is not very accurate and consistent. Data preprocessing is indeed a challenge of its own because there are multiple ways to do it as per different requirements. I also realized that data preprocessing actually makes the succeeding steps in data analysis quite straightforward.
References:
https://developer.ibm.com/technologies/data-science/articles/data-preprocessing-in-detail/
https://www.upgrad.com/blog/data-cleaning-techniques/#Data_Cleansing_Techniques
IS590PD – Practical Health Analytics Project, SP2020, UIUC