1. Introduction
Multi-task learning aims to combine several learning tasks into a singular framework or architecture with the goal of improving accuracy or efficiency. Success has been seen in many vision tasks through the use of convolutional neural networks (CNN): classification, semantic segmentation, object detection, pose estimation, etc. However, the architectures developed for these tasks typically only predict a single output. In scenarios where several forms of predicted labels are required, using multiple trained networks is both computationally expensive and memory inefficient. When deploying to mobile platforms or embedded devices it is critical that vision architectures are efficient and are within the bounds of limitation.
There is a wide array of CNN architectures that have been developed as effective feature extractors. The feature maps extracted from these CNN’s contain rich visual features that are useful for tasks other than classification. Using this idea, we propose an architecture that utilizes shared feature maps extracted from a CNN backbone in order to predict more than one output.
Another way to improve efficiency is to build CNN architectures that are lightweight and contain lower numbers of parameters. We develop and test an efficient depth estimation network using MobileNet V2 [1] as the CNN feature extractor and compare our network to another depth estimation network that is deeper and contains significantly more parameters.
2. Related Work
MobileNetV2 is a computationally light feature extraction architecture which works by doing depth wise separable convolutions (which are basically stackings of depth-wise and pointwise convolutions) with an inverted residual structure [1]. Advancements in CNN’s did not necessarily improve efficiency in terms of speed and resource utilization. MobileNetV2 was built to target design requirements of embedded devices with limited computation, power space and internet connection. It has a top-1 and top -5 accuracy of 74.7 and 91.0 on ImageNet [1].
It has been shown empirically that deeper neural networks work better (i.e. learn more complex functions) than shallower ones. Building deeper networks however, is not as easy as adding more convolutional layers. This often results in problems such as exploding or vanishing
gradients. The gradient problems have been addressed to a large extent by using normalized initializations. Though convergence issues were resolved, degradation problems
Architecture | Frames Per Second | Parameters |
MobileNetV2 | 36.7 | ~2.4 M |
ResNet-50 | 29.1 | ~75.1 M |
started cropping up; with increasing network depth, accuracies would get saturated. For this reason, residual networks such as ResNet-50 and the other ResNet architectures were developed. The basic idea is to to fit the data to a residual mapping . We train the neural network to map and recast the data to to predict the mapping . This is done using skip connections. The input is added back to the learned mapping in residual layers. He, et al. have shown us that these kinds of residual architectures are able to overcome the accuracy saturation problem encountered while training deeper neural nets.
As the name suggests, the Single Shot Detection architecture does object detection/recognition in a single forward pass through the network [3]. This eliminates the need of two shots used for generating proposal, usually used by regional proposal network (RPN) based network such as Faster-RCNN. While making the process faster it
can match the accuracy of RPN based network with lower resolution images. It is a stacking of auxiliary convolutional layers which progressively scale down to decrease the size of the input to each subsequent layer. SSD uses VGG16 to extract feature maps and the auxiliary layers are added at the end of base networks which individually make a set of detection predictions. This improves the performance and accuracy compared to other single shot detectors.
Traditional approaches of depth estimation included using hardware support (like IR lasers, depth estimating cameras like the Kinect and stereo vision approaches) but using CNN architectures described in [5] and [4] give us a distinct advantage as they repurpose high performing pre-trained networks that are originally designed for image classification as our deep features encoder, allowing for a more modular architecture. Using such a stacked neural network ensures that advances in object detection automatically transfer to our depth estimation problem.
Ubernet [7] was developed to address the problems of training universal CNN which include limited memory during training and diverse data sets with many types of labels. Ubernet consists of a CNN trunk which computes feature maps that are shared among task-specific branches that consist of other CNN layers. Kokkinos proposes a memory efficient method of training a universal CNN along with an asynchronous algorithm of updating shared CNN parameters among the task-specific branches.
3. Proposed Method
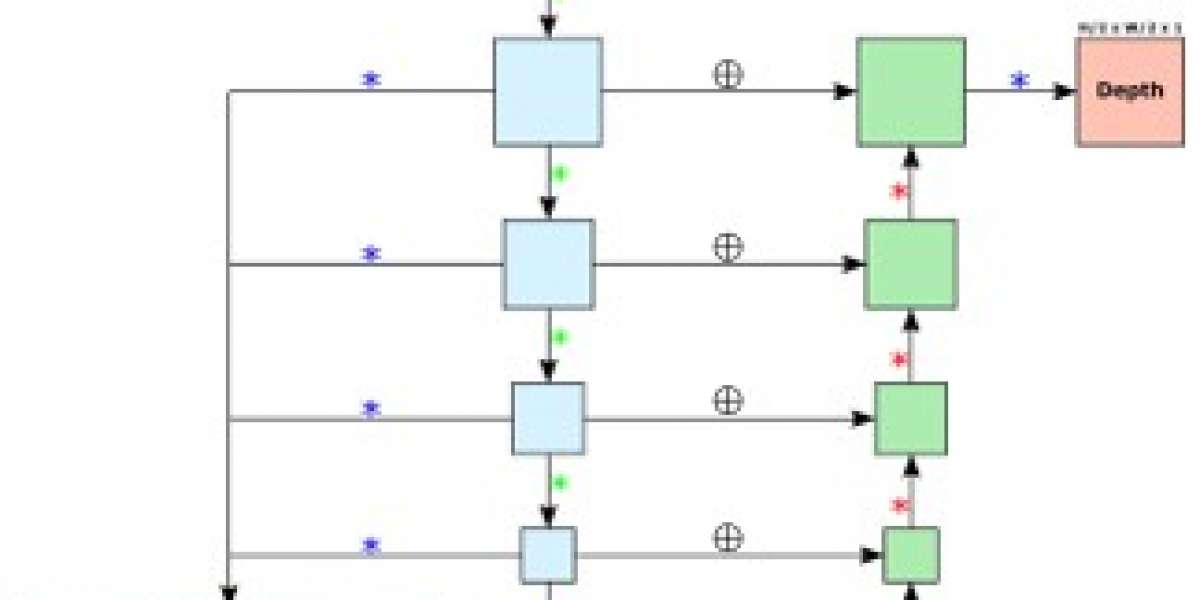
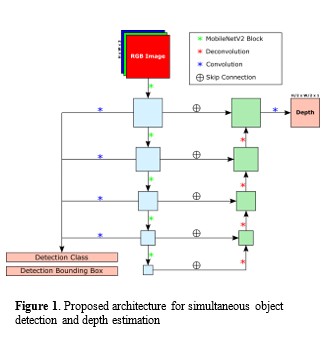
Our method includes a novel architecture that shares features for predicting multiple outputs. At the core of this architecture is a feature extracting backbone that outputs feature maps at several down-sampled spatial resolutions containing high and low-level features. MobileNetV2 is the feature extracting CNN backbone due to its efficiency in terms of memory and number of computations. The feature maps computed using the MobileNetV2 backbone are fed to two separate branches, one for depth estimation and the other for object detection.
The object detection branch is modeled after the SSD architecture in [3]. Each feature map from the MobileNetV2 backbone will undergo one more convolutional layer to predict bounding boxes and detection classes for each spatial index of the resulting feature map. This allows bounding boxes of different shapes and scales to be accurately predicted. Since similar bounding boxes may be predicted for the same object at different levels of the MobileNetV2 backbone, non-maximum suppression will take place to filter similar bounding boxes.
The depth estimation branch will be modeled after the DenseDepth architecture outlined in [5] which includes a
pretrained feature extracting backbone accompanied by an up-sampling branch to predict the final depth map. Our variation to this architecture is a more efficient feature extracting backbone for feature extraction and an up-sampling branch that uses deconvolutions (transposed convolutions stride 2) instead of bilinear up-sampling followed by convolutions.
The loss function for the depth branch consists of two components. A pixel-wise L1 loss will be applied to the target depth map and predicted depth map using (1).
The mean-squared error (MSE) (2) of the image gradient magnitudes and will be computed as the second component of the depth loss function where . This component of the depth loss function ensures that incorrect object boundaries are penalized
during training which results in sharper depth predictions with clearer boundaries.
The object detection branch also undergoes two different loss functions in order to optimize the bounding box outputs and class predictions for each detected object. A cross-entropy loss is applied to the class predictions using (3), and a smooth-L1 loss (4) is used for the regressed bounding boxes.
Where .
Output | Rel | RMSE | log10 | |||
Depth Map | 0.704 | 0.908 | 0.973 | 2.404 | 1.670 | 0.083 |
People | 0.724 | 0.943 | 0.968 | 0.148 | 0.983 | 0.072 |
Vehicles | 0.899 | 0.987 | 0.998 | 0.101 | 1.061 | 0.0450 |
Output | Rel | RMSE | log10 | |||
Depth Map | 0.691 | 0.900 | 0.974 | 2.353 | 1.703 | 0.085 |
People | 0.748 | 0.895 | 0.984 | 0.165 | 1.099 | 0.082 |
Vehicles | 0.872 | 0.985 | 0.997 | 0.110 | 1.110 | 0.050 |
4. Experiments
- KITTI Dataset
The KITTI dataset [6] was created to establish computer vision benchmarks for real-world applications in city-like environments. This dataset contains a large set of images accompanied by many different labels such as depth maps created from LIDAR and bounding box annotations for objects.
There are 7,481 RGB images with object labels with a total of 80,256 bounding box labels. For depth estimation, there are ~93,000 RGB image and depth map pairs. The raw depth maps have many missing values as a consequence of the LIDAR hardware therefore we use the same colorizing algorithm to fill in missing values as [5]. We train on the full set of training images for depth estimation and evaluate our depth estimation network using a validation subset of 6,852 RGB image and depth mask pairs. For evaluating object specific depth estimation, we use 1,069 RGB images from the depth validation set that contain both object labels and depth labels.
- Training
Our depth estimation experiments are carried out using the deep learning library PyTorch and trained on a desktop using a single NVIDIA 2080Ti with 11GB of memory. We train on the KITTI depth estimation dataset for 20,000 iterations with a batch size of 4. We utilize Adam optimization to fit the parameters of the network with an initial learning rate of 1e-3 with an exponential decay of 0.9 every 500 iterations. Betas 0.9 and 0.999 are used as the momentum terms and a weight decay coefficient of 1e-5.
We repeat this experiment twice with two different CNN feature extractors: ResNet-50 and MobileNet V2. An overview of these two architectures can be found in Table 1.
- Evaluation
The validation set of 6,852 RGB image and depth mask pairs is used for evaluating the performance of our depth estimation experiments. Six different metrics are used to evaluate the depth estimation accuracy and error. We use these metrics for predicted depth maps and ground truth depth maps and extend this to specific object depths using the mean depth value for a given object label in the 1,069 RGB images that have both depth labels and object labels.
The accuracy (5) is a ratio of pixels that do not exceed a certain ratio between the depth prediction ground truth depth map. The higher the value the more accurate the depth prediction. The accuracy is calculated using three different thresholds .
There are three error calculations (6), (7), and (8) that measure slightly different forms of error. The smaller the number, the more accurate the depth prediction.
5. Results
We first compare the two different depth estimation networks in terms of speed and memory usage in Table 1. We find that there are similar frame rates between MobileNet V2 (36.7 FPS) and ResNet-50 (29.1 FPS) with MobileNet V2 having a frame rate ~26% faster than ResNet-50. There are drastic differences between the number of parameters in the two networks which is the primary metric for memory usage in this case. ResNet-50 has roughly 35 times the amount of parameters compared to MobileNet V2 with 75.1 million parameters versus 2.4 million parameters.
We analyze the results of our depth estimation comparing Table 2 and Table 3. The ResNet-50 architecture outperforms the MobileNetV2 architecture in 14 of the 18 depth metrics. When predicting depth maps, MobileNet V2 achieved a better relative error and accuracy compared to ResNet-50. When predicting average depth for the People category, MobileNet V2 achieved higher and accuracies compared to ResNet-50. ResNet-50 had better results in all metrics when predicting average depth in the Vehicle category compared to MobileNetV2.
6. Conclusion
In this work we propose a computationally efficient architecture for simultaneous depth estimation and object detection. We draw inspiration from multi-task learning frameworks such as [7] to design a CNN architecture that shares features in order to predict more one than output. Many task specific frameworks such as Faster-RCNN, SSD, or DenseDepth utilize popular CNN feature extractors such as ResNet-50 or MobileNet V2 in their architectures because of their ability to learn rich visual features from the data. Therefore, we propose an architecture that uses MobileNet V2 as the feature extracting CNN backbone and two task-specific branches that perform object detection and depth estimation. Each branch shares the same features extracted from MobileNet V2. The depth estimation branch is a decoder style network with skip connections that takes feature maps from the previous layer and performs deconvolutions with stride 2. The object detection branch is a light-weight network SSD that predicts bounding boxes and class labels using each feature map from the different stages of MobileNet V2 as input.
We perform depth estimation experiments to evaluate a MobileNet V2-based depth estimator. We found that a ResNet-50-based architecture outperformed the MobileNet V2 in nearly all metrics (14 out of 18). With that said MobileNet V2 was worse on average by only 5.52% despite being 26% faster with 35 times less parameters. We therefore conclude that MobileNet V2 is an efficient depth estimation architecture well-suited for constrained applications such as mobile computing or embedded devices.
In the future we hope to implement our proposed multi-purpose architecture for simultaneous depth estimation and object detection and conduct experiments using the KITTI dataset. Such multi-purpose networks will be integral for high-level scene understanding.
References
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
- Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg. SSD: Single shot multibox detector. European conference on computer vision. 2016.
- David Eigen, Christian Puhrsch, Rob Fergus. Depth map prediction from a single image using a multi-scale deep network. Advances in neural information processing systems. 2014.
- Alhashim Ibraheem, and Peter Wonka. High Quality Monocular Depth Estimation via Transfer Learning. arXiv preprint arXiv:1812.11941. 2018.
- Andreas Geiger, Philip Lenz, Christoph Stiller, Raquel Urtasun. Vision meets robotics: The KITTI dataset. The International Journal of Robotics Research. 2013.
- Iasonas Kokkinos. Ubernet: Training a universal convolutional neural network for low-, mid-, and high-level vision using diverse datasets and limited memory. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017.