1. Search tool architecture
1.1 Video Dataset
The V3C1 dataset is composed of 7,475 videos. The mean duration time of videos is 481 seconds. Each video is segmented into a set of short clips, and each short clip is represented by a keyframe. On average, the number of generated short clips per video is 145, and the mean duration time of clips is 3.2 seconds. The total number of generated clips for the whole video dataset is 1,082,657; therefore, the V3C1 dataset is represented by a set of 1,082,657 keyframes (i.e., images). Now, the video search task gets transformed into image search.
1.2 Query Tasks
Using the reference video dataset, IVS supports three types of queries: Visual Known Item Search (Visual KIS), Textual Known Item Search (Textual KIS), and Ad-hoc Video Search (AVS). Each of these query types aims at retrieving the keyframes that satisfy the query criteria.
The Visual KIS query enables a user to search within the reference video dataset for keyframes similar to the scenes depicted in a given 20-second clip. Meanwhile, with the Textual KIS query, the user provides a detailed text description instead of a video to search for keyframes capturing scenes that satisfy the query description. The AVS query is similar to the Textual KIS query as both of them are based on a textual description of the target scene. However, they are different in the number of the desired query results. In particular, the Textual KIS query aims to find the best keyframe that matches the query criteria while the AVS query expects to find a set of keyframes satisfying the target scene description.
1.3 Image Representation Metadata
Image search depends on the availability of rich image descriptors that depict various aspects of the image properties. Without loss of generality, IVS uses the following metadata as descriptors for the dataset.
– Detected Objects: One way of describing images is to specify the objects captured in images. For this sake, several deep learning methods for image recognition and object detection can be used. Each keyframe in the V3C1 video dataset is associated with a subset of the 1000 objects detectable by the NASnet convolutional neural network. Given that each detected object is associated with a detection confidence score, we consider only the first ten objects with the highest confidence scores to reduce the impact of detection inaccuracy in searching. Furthermore, given that the NASnet algorithm annotates the detected object in a general and abstract manner (e.g., person), we have considered another state-of-the-art object detection algorithm (known as DenseCap) which detects objects with more detailed annotations (e.g., a person playing baseball); hence, adding more contextual information about objects.
– Faces: The keyframes of the V3C1 dataset are augmented with the set of human faces that have been detected via the Apple Image Core API2. This API reports different labels that imply the number of the detected faces (i.e., no faces, one face, two faces, three faces, four faces, or many faces). Since the face detection implies a person’s existence, IVS utilizes the metadata extracted from the face detection analysis as indicators for persons in the search approach.
– Visual features: Various approaches have been proposed for extracting visual features that depict the visual content of an image (e.g., colour histogram, edge histogram, and SIFT). The keyframes of the V3C1 dataset are associated with visual features consisted of colour and edge histograms. In addition, we used one of the recent state-of-the-art approaches (referred to as regional maximum activations of convolutions (R-MAC)), which utilizes a deep neural network for learning features from an image. R- MAC extracts a feature vector composed of 512 dimensions.
– Detected Text: Optical character recognition(OCR)enables extracting the written text that appears in certain portions of images (e.g., the text written on a traffic sign or a shop storefront captured in an image). Given that a subset of the keyframes of the V3C1 dataset is labelled with few or much text (based on the analysis results via the Apple Image Core API for recognizing text), we have extracted text from this subset using TesseractOCR. Furthermore, since some short clips of the V3C1 dataset include speech, such clips have been analyzed by the Google Cloud Speech-to-Text API to extract spoken keywords to tag them with their corresponding keyframes. For both texts extracted by either OCR or speech recognition, it has been processed to filter out the non-English text and invalid English words using the Python language detection and the part-of-speech tagging libraries, respectively.
– Dominant Color: Each keyframe in the V3C1 dataset is labelled with the dominant colour. The dominant colour is either one of the colours: blue, cyan, grey, green, magenta, orange, red, violet, yellow, black/white, or undetermined.
1.4 Storage and Indexing
To enhance the search performance of IVS, we have stored and indexed the metadata of the reference video dataset into two different database engines. First, the textual metadata (i.e., detected objects, faces, detected texts, and dominant colours) are stored into Whoosh which is a pure-python full-text search engine library. Using Whoosh, each keyframe is considered a document that is represented by keywords categorized into predefined categories (i.e., detected objects, faces, detected texts, and dominant colours). [Make the following sentence clear.] These keyframes their corresponding keywords are organized in an inverted index file. After that, the keyframes are retrieved based on the well- known text-based retrieval methods (e.g., TF-IDF and the Okapi BM25F ranking functions). Second, the visual features are stored in PostgreSQL. Since each keyframe is represented by a high-dimensional vector, PostgreSQL enables storing such high-dimensional data in a special data type known as “cube” that supports organizing data using a Generalized Search Tree-based index (GiST); hence supporting efficient k-nearest neighbour (kNN) queries.
1.5 Searching Approach
Query Parsing and Preprocessing. For executing the text-based queries (i.e., Textual KIS and AVS), the textual description of a query needs to be interpreted. Thus, a natural language processing (NLP) library is used to interpret the query text to extract meaningful keywords and discard unnecessary ones (e.g., stop words and punctuation). In IVS, an NLP library called SpaCy is used. The extracted keywords are classified into adjectives, nouns, verbs, and numeric keywords. Thereafter, these words are mapped to predefined terms in the tool dictionary representing the objects, colours, and faces. Then, the mapped terms are used for searching the video dataset by utilizing the built indexes. For example, if the query includes the word “turquoise”, it is mapped to the set of primary colours that constitute that specific target colour (e.g., turquoise is mapped to blue and green) for utilizing the colour metadata while searching. Also, if the query includes the word “a man”, it is mapped into “one face” for utilizing the face metadata.
Regarding the visual-based queries (i.e., Visual KIS ), the provided 20-seconds video is segmented to extract a set of keyframes. Then, the extracted keyframes (referred to as query keyframes) are processed to generate a visual feature descriptor per each. Moreover, each of the query keyframes is processed using object detection, speech recognition, and character recognition algorithms to identify its textual keywords. Both visual feature descriptors and textual keywords are used for searching the video dataset.
Retrieval and Ranking - For the textual queries, the keywords identified through the query parsing and preprocessing are used to search the textual metadata dataset utilizing the built indexes within the search tool. Given that the metadata is stored into different categories, each of the query keywords is mapped to a specific metadata category. At executing the search query, the text indexes corresponding to each metadata category are employed to retrieve the best keyframes associated with keywords matching the query keywords. Then, the retrieved keyframes are ranked using either the TF-IDF or BM25 scoring functions (based on user selection) supported by Whoosh. The query keywords are prioritized based on their corresponding categories. Based on our evaluation, we found that detected object metadata are the most essential for finding relevant keyframes. Therefore, keywords related to the detected object category have a higher priority than the others; however, the other keywords are used to increase the priority of the retrieved keyframes matching both detected object keywords and other keywords. In IVS, the prioritizing mechanism of the search results is implemented using a Boolean query as outlined below.
T extQuery = {keywords(category : DetectedObjects)} OR
{keywords(category : DetectedObjects) AND keywords(category : Others)}
On the other hand, for the visual queries, for each query keyframe, two queries are executed: visual-based search using the extracted visual feature descriptors and text-based using the extracted textual keywords. Each search ranks the retrieved keyframes individually using some ranking functions. The text search ranks the keyframes using TF-IDF or BM25 while the visual search ranks them using a distance-based similarity function (either Euclidean or cosine distance based on user preference). Thereafter, the common keyframes retrieved from both visual-based and text-based search are kept, but their ranking scores are aggregated from both search mechanisms.
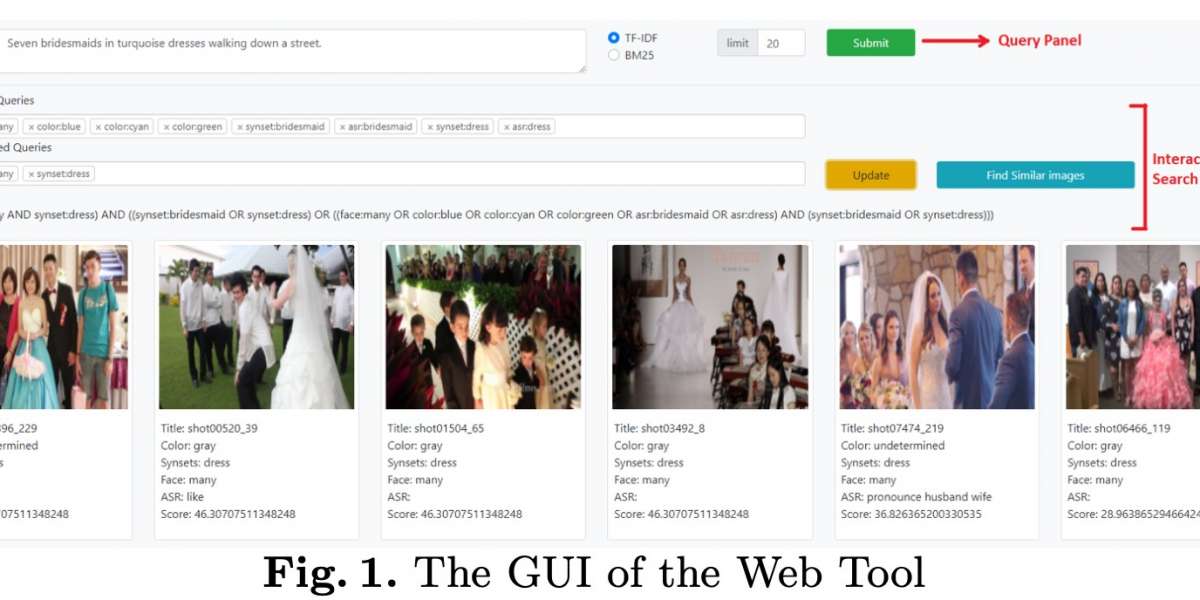
Interactive Search - I V S provides two mechanisms for interactive search. First, a user can help in updating the parsing results of the textual query. In particular, the user can delete or add some keywords. Moreover, the user can participate in emphasizing higher priority for some keywords. The high-priority keywords are combined with the “and” operator in the Boolean query composing the textual query. Second, the user can provide feedback for the retrieved results of a query by selecting relevant keyframes among the retrieved ones. Thereafter, a visual search is executed to retrieve similar reference keyframes to each of the relevant keyframes.
T extQuery = ({keywords(category : DetectedObjects)} OR
{keywords(category : DetectedObjects) AND keywords(category : Others)}) AND {keywords(category : ⋆ and emphasized)}
2 Conclusion
This blog discusses about an interactive video search tool (IVS). The IVS tool supports both textual and visual queries and aims at providing an efficient and accurate search utilizing various metadata types and hence different indexing techniques. In addition, the IVS tool enables getting users’ feedback either by customizing the query or by relevance feedback [”by relevance feedback” or ”by adjusting relevance”] to enhance the search results.