[0] References
- https://patents.google.com/patent/US6105025
- https://patents.google.com/patent/US6453314B1/en
- https://15721.courses.cs.cmu.edu/spring2019/slides/01-inmemory.pdf
[1] Requirement
- Check unique constraint at the point the end of transaction.
[2] Main Idea
- Enable unique index stores duplicate indexed data vvalues during transaction processing.
- Keep unique constraint violation count which is the number of duplicate entires in the index.
[3] Design
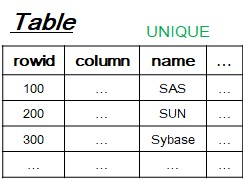
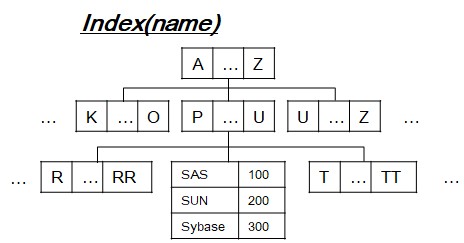
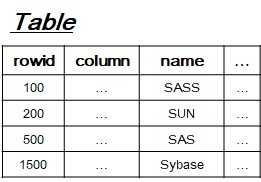
[3-0] Basic Environment
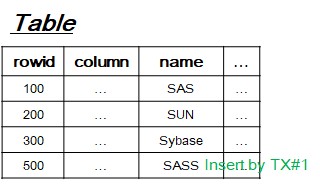
- create table test (name unique, .....);
- DBMS engine build unique index tree (Almost B+ tree) like that.
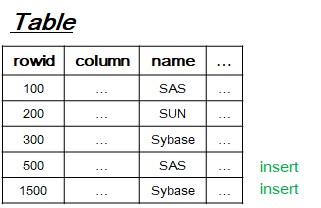
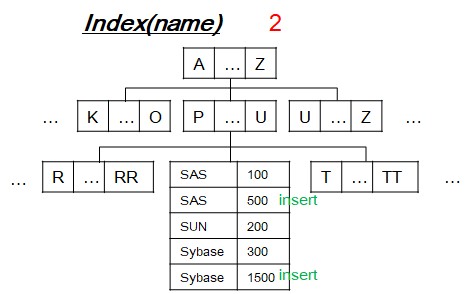
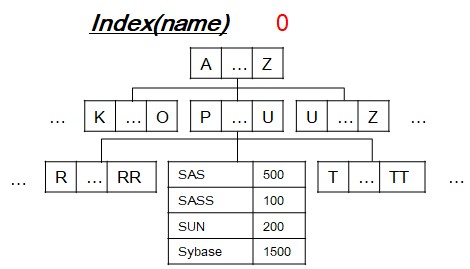
[3-1] Insert operation
- Search leaf-node to insert new value with row-identification(a.k.a. rowid).
- If duplicate, then increment unique constraint violation count by 1.
- After processing two insert DML, unique index tree becomes like that in order above idea.
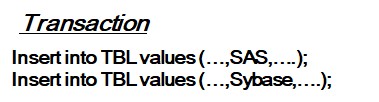
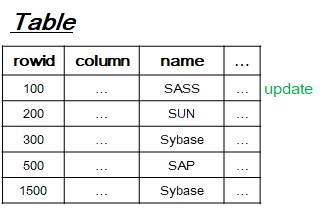
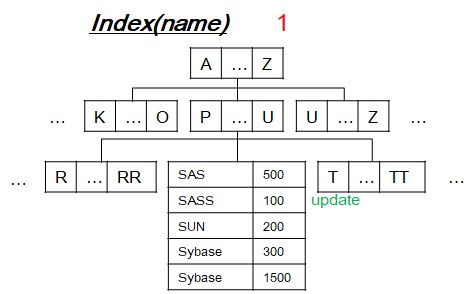
[3-2] Update operation
- Search leaf-node to update from old value to new value.
- If old value is only one occurrence, then reduce unique constarint violation count by 1.
- If new value is duplicate, then increment unique constraint violation count by 1.
- After processing one update DML, unique index tree becomes like that in order above idea.
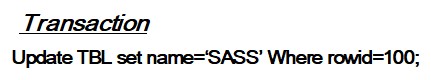
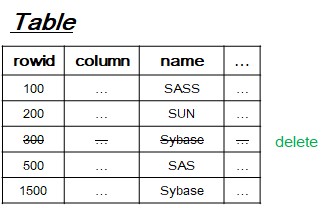
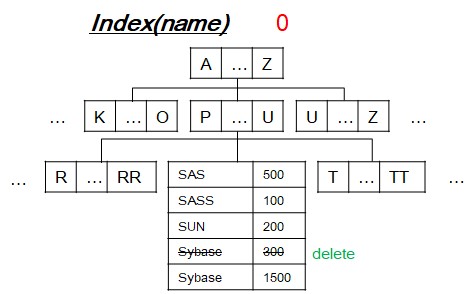
[3-3] Delete operation
- Search leaf-node to delete old row.
- If old row is only one occurrence, then reduce unique constarint violation count by 1.
- After processing one delete DML, unique index tree becomes like that in order above idea.

[3-4] Commit operation (End of transaction)
- If unique constarint violation count is 0, then commit.
- If unique constarint violation count is not 0, then rollback.
- After processing commit operation, the unique violation count is 0. So, commited.

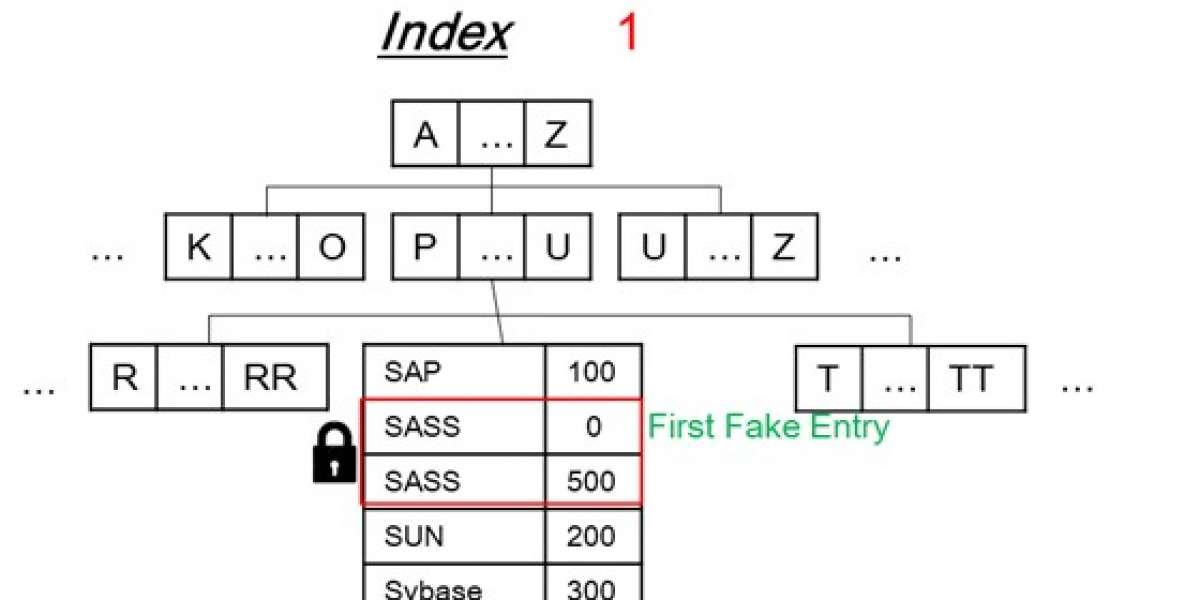
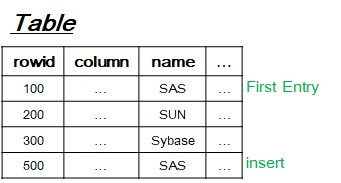
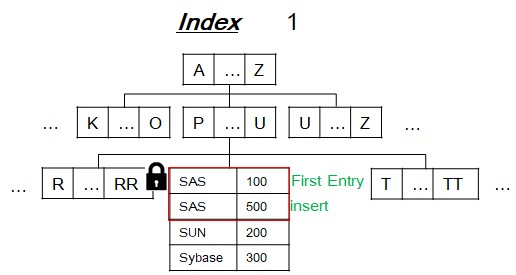
[4] Challenge - Concurrency?
- Same with index locking(Gap locking, Key-Range Locking, Hierarchical locking).
- Use entry exclusive lock to first entry which is already exising entry.
- TX#1 blocked TX2 by locking entry exclusivley.

- If not, then insert fake first entry and lock fake first entry.

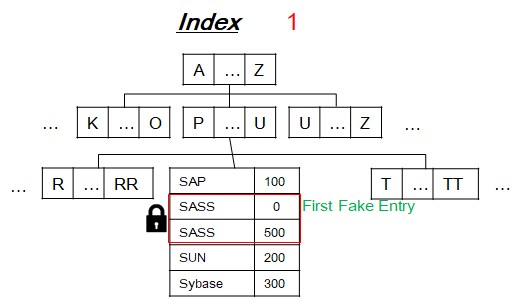
- TX#1 blocked TX#2 by locking first entry which is fake.
[5] Summary
- The deferred unique constraint checking provides a uniqueness-required index and a corresponding non-uniqueness count to support deferred uniqueness constraint enforcement. A uniqueness-required index stores duplicate occurrences of indexed data values that occur during statement or transaction processing. The non-uniqueness count associated with the uniqueness-required index provides a count of the number of indexed data values that occur more than once in the index. Where a non-uniqueness count is not equal to zero, a uniqueness constraint violation remains unresolved. Where an unresolved constraint violation exists at enforcement time, the effects of the processing are removed, rollbacked,. A currently non-unique count can be used to represent the number of uniqueness-required indexes that are "currently non-unique". The currently non-unique count can be examined to determine whether there are any unresolved uniqueness constraint violations. Constraints can be enforced at the end of the processing of a transaction, or within a transaction at a savepoint.