I. Executive Summary
Many start-ups are rapidly entering the market and providing either services or products to consumers today. These businesses differ a lot in management structure, financial architecture and in their approach towards organizational security from the bigger organizations and from each other.
The ensuing report will discuss how small, medium and large enterprises are defined in terms of employee count, geographical spread, annual revenue and expenditure, etc. This will be followed by different approaches to achieve security in each enterprise, and a comparison between them. The large enterprise, which is JP Morgan Chase, in this case, will be then analyzed and evaluated for risks and their costs.
Analysis shows that JP Morgan Chase has 21 vulnerabilities and its subsidiary, Chase Bank has 102 of them. These when evaluated, result in endpoint devices and application software being the most prevalent vulnerabilities (31%) that cause the most impactful risks. All such risks will be discussed along with their urgency and impact.
Then, there will be a section discussing the controls that can be implemented to avoid or mitigate these risks. These controls will be categorized as preventive (14 in number), detective (4 in number), audit (1 in number) and forensic (1 in number). They will be compared to the risks that they control and to each other as well based on their cost and effectiveness.
Speaking of cost, there will be a section that will discuss the cost of implementing these controls, both monetary and non-monetary. Three different budgets will be presented: 1. Minimal, 2. Practical, and 3. Money-not-a-problem budget. These budgets will range from $11mn to $12.5mn which is not a very big difference but is surely a huge number. However, as JP Morgan Chase is a big and rich company, it can afford to implement this budget and the controls that are mentioned in them.
Finally, the report will discuss which controls are the weakest, how they can be normalized, how the needs of the enterprise compare to its value and other graphs that indicate or interpret related statistics.
II. Models of Definition
Based on factors such as size, the number of employees, annual revenue, etc., an organization can be classified into 3 major categories:
- Small and Medium Businesses
- Small and Medium Enterprises
- Large Enterprises
However, different people use different parameters to categorize organizations into these three. On doing some research, I found that there were some points that were common between them, and some which were contrasting. So, before building a proper definition of these, I thought it best to compare and contrast them.
My first source, Digium [4] defines them in its article in the following manner.
- Small to Medium Businesses: Small businesses are the ones that have around 100 employees, while medium businesses are those that have around 1000. Their annual revenue is around $10mn, have very few people with perfunctory skills for IT, are geographically limited and due to less capital revenue, they invest in technologies that are cheap and easy-to-use.
- Small to Medium Enterprises: They are the ones that have around 500 employees,their annual revenue is around $75-80mn, have a group with generalist skills for IT, are geographically limited to one country and due to an okay capital revenue, they invest in technologies that provide functionalities, are capable and can report bugs or errors.
- Large Enterprises: They are the ones that have more than 1000 employees, their annual revenue is much more than $1bn, have a complete module for IT with people having special kills as well, are geographically multinational and due to a huge capital revenue, they can invest in technologies that provide guaranteed up-time, advanced features and also security.
OpenLearn [5] on the other hand, defines these categories in the following manner:
- Small to Medium Businesses: They have around 50 employees, their annual revenue is around 10mn Euro, are geographically limited and they invest in technologies that are cheap.
- Small to Medium Enterprises: They are the ones that have around 250 employees, have an annual revenue of around 50mn Euro, are geographically limited to one country and invest in technologies that provide functionalities.
- Large Enterprises: They are the ones that have more than 250 employees, their annual revenue is much more than 50mn Euro, are geographically multinational and due to a huge capital revenue, they can invest in technologies that provide advanced features and even security.
Finally, Gartner [6] also uses the same parameters as Digium [4] to classify organizations. However, they consider Small and Midsize Businesses to be the same as Small and Midsize Enterprises. Their parameters and their values for the rest two, fall exactly in-line with each other.
Building on the aforesaid, I came upon the following definitions:
- Small and Medium Businesses: These are those businesses which have an average turnover of $10mn, employ an average of 500 employees, operate in a limited geography, have very few on-site staff to manage IT, and due to very limited capital buy only those technologies which are cheap and easy to use.
- Small and Medium Enterprises: These are those businesses which have an average turnover of $75-80mn, employ an average of 1000 employees, operate in a single country, have a group of on-site generalists to manage IT, and can buy those technologies which provide functionality with decent capabilities.
- Large Enterprises: These are those businesses which have an average turnover of billions, employ thousands of local and remote employees, operate in multiple countries, have very a dedicated on-site staff to manage IT, and due to very high capital buy those technologies which provide higher level, advanced features and can also buy costly tools for security
III. General model to categorize organizations
Building on the above, I came up with the following categorization model which can categorize any company, given the following input parameters:
- Number of employees- This gives an estimate of how many teams work in an organization, what average salary is being paid to each one of them, how they can be trained in the latest technologies, and how efficiently they can work.
- Annual Revenue- This gives an estimate of how much the organization earns, and from which product or service. While potential investors can analyze this revenue and seek to invest, potential customers/business partners can do the same and seek to buy or partner.
- Capital Expenditure- This gives an estimate of the areas where an organization is willing to invest.
- Geographical Spread- This gives an estimate of how popular a brand related to the organization is. This also gives an idea of the influence of an organization over the economy of a country, the daily lives of people and international trade markets.
- Investment Patterns- These are the patterns investment defined by the capital expenditure of an organization. They define the goal that the organization is moving towards.
- On-site IT staff- This gives an idea of the organization’s willingness to maintain a good quality of network and communication. This could also include the security of the same.
As per me, these should be the general templates for all organizations:
TABLE I
Small and Medium Businesses
Parameter | Value |
Number of Employees | 100-1000 |
Annual Revenue | $5-10 million |
Capital Expenditure | Very limited |
Geographical Spread | Local to a state or multiple states |
Investment Patterns | Cheap and easy technology |
TABLE II
Small and Medium Enterprises
Parameter | Value |
Number of Employees | 500-1000 |
Annual Revenue | $10-1000 million |
Capital Expenditure | Just enough |
Geographical Spread | Uninational |
Investment Patterns | Functional and capable technology |
TABLE III
Large Enterprises
Parameter | Value |
Number of Employees | 1000 |
Annual Revenue | $1 billion |
Capital Expenditure | Very high |
Geographical Spread | Multinational |
Investment Patterns | Optimized, advanced and secure technology |
IV. Use cases
- Small to Medium Businesses: Small Business Trends is one such company that falls into this category. According to Owler, it employs 6 employees and has an annual revenue of $1.6mn. It is an online publication and has its office in Florida.
- Small to Medium Enterprises: An example of such an enterprise is the New York-based start-up LeafLink [7]. According to Crunchbase [8], it currently has around 50 employees, serves around 2500 retailers across 15 states in the US and has an annual revenue of $14mn. It is funded by only 1 investor. It invests majorly in software such as SaaS, cannabis, etc. which provide the functionality required to keep their enterprise going. This is hence going towards the medium enterprise category.
- Large Enterprises: An example of such an enterprise is JP Morgan Chase [9]. According to its site [9], it currently has around 250,000 employees, has an annual revenue of over $100bn [10], and has offices in over 100 countries. It invests majorly in investment banking, financial services for consumers and small businesses, commercial banking, financial transaction processing and asset management It falls in the I quadrant of the cash-flow quadrant, and seeks to invest in advanced and secure features.
V. Security Risks
- Common risks: There are some risks which are common to organizations irrespective of their size/category:
- Reputational Risk- This is a risk to the reputation of the organization which can be tarnished either by entities posing to be the organization and harassing its customers or by competitors who advertise it in a bad light. [11]
- User Risk- This is a risk which can rarely be dealt with as users are the weakest link in a system. Any attack on the users’ end-devices can mean harm to them, and to the organization’s business.
- Availability Risk- A DoS or DDoS attack can be performed on any organization, and handling them is proportionately difficult for them.
- Disasters - Any natural disasters like cyclones, tornadoes, floods, fires, etc could be possible, and they cause a lot of damage.
- Defamation - This is also a risk which could be caused by the wrong actions of an employee, or by a competitor who wants to tarnish the enterprise’s reputation, thereby affecting its customer base and business relations.
- Specific Risks: Then there are risks that are specific to the size/category of the organization. For small to medium businesses or enterprises, I feel that these are the risks that such organizations should foresee, but most do not:
- Operational Risk- Risk of loss resulting from inadequate or failed internal processes, people and systems, or from external events. Operational risk may include the risk of loss resulting from legal and regulatory noncompliance. [11]
- Systemic Risk- Systemic risk is the risk of default or a loss that affects an entire network or system. A loss experienced by one participant or member can affect one or more others, or potentially harm the entire system. [11]
- Economic Risk - These are the risks that are faced by all the organizations but the levels at which they experience them are very different. Even the nature of such risks is quite different.
VI. Vulnerabilities and Risks
In this section, there will be discussion about the potential vulnerabilities in JP Morgan Chase and its subsidiary Chase banks system and network infrastructure, the risks that they give birth to, and ways to mitigate them.
It will consist a summary of what vulnerabilities I observed and researched, the sources from where I got them, and the potential risks that these vulnerabilities might give way to.
To estimate the level of risk, I have used the Probability-Impact matrix which projects the intersection or overlap of the probability and impact matrices as a risk matrix and assigns each region a level of intensity.
- Vulnerabilities observed by me - summed up [1]
- Have a big database of critical public information SSNs, PCI data, account data, etc.
- Record what website we came from, what OS we are running, what browser, and where we will go.
- These cookies are also shared with their 3rd-party partners, which are either not as trustworthy or are weaker against attacks.
- Collect user information from 3rd party sources and relate it to their information. If these sources get known to attackers, they might attack them instead of the bank.
- The information of users is shared across countries and continents. This makes it vulnerable to attack on the way, or at any entry/exit points like Autonomous Systems or routers.
- Vulnerabilities as researched by me using CVE by MITRE
Table IV
Vulnerabilities Found In JP Morgan Chase
Vulnerability-type | Number of such vulnerabilities |
Cross-site scripting | 7 |
Static PHP code injections | 5 |
DoS and Buffer Overflow | 3 |
SQL injections | 2 |
Application and Server security | 2 |
- For JP Morgan Chase 16 vulnerabilities summed up [2]:
- An attacker may use the format parameter in a JS query, to inject random commands in the npm package morgan 1.9.1
- Software like CS-Cart Japanese Edition allow remote attackers to bypass access restrictions and authorization procedures to create a request that returns customer purchased items back.
- Multiple instances (7 in specific) of either cross-site scripting that allows attackers to inject malicious JavaScript code or HTML code.
- The Android application for Chase mobile does not verify whether the server hostname matches a domain name in the Common Name field of a subject, in its X.509 certificate. This allows a successful Man-in-the-Middle attack.
- They used a Linux kernel version that was lower than 3.7.4, and that had a port vulnerability that allowed Denial of Service attacks (NULL pointer dereferencing and system crashing)
- Many vulnerabilities that allow either local or remote users to obtain critical information like authentication information or account information via unspecified vectors.
Table V
Vulnerabilities Found In Chase bank
Vulnerability-type | Number of such vulnerabilities |
Application and Server security | 22 |
Cross-site scripting | 8 |
DoS and Buffer Overflow | 5 |
SQL injections | 3 |
Static PHP code injections | 3 |
2. For Chase bank 97 vulnerabilities summed up [3]:
- 8 instances of cross-site scripting that again allowed injections of malicious web script and HTML.
- 8 instances of SQL injections that allowed attackers to run arbitrary SQL commands and mess with the database by performing random transactions and procedures.
- 22 instances of issues with the Android application ranging from some of them indicating storage of credentials in plaintext, to some of them indicating zero verification of SSL and X.509 certificates thereby allowing MitM attacks. Some issues also addressed specific problems like the creation of unprotected and sensitive log files and certain versions of Android not being able to properly connect to access points thereby allowing attackers to obtain critical information by gaining access to an 802.11 network.
- 5 instances where a DoS attack could be made possible due to openings in firmware or installation of unsafe applications.
- 3 instances where an attacker could inject and run a malicious static PHP code on a machine via a PHP shell or a URL.
- 3 instances where an arbitrary code can be injected, and when run leads to a Buffer Overflow and ultimately a system crash.
VII. Risks born due to these vulnerabilities The Probability-Impact matrix
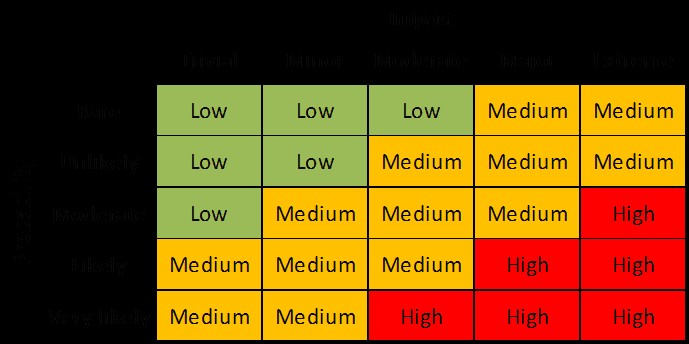
The Probability-Impact matrix for risk assessment
This image has been copied from [12]
The vulnerabilities mentioned above give birth to many risks once threat vectors come into play -
- The biggest and most prevalent vulnerability that I observed during my research was in the Android application and the internal system endpoints. This means that Application Security, Endpoint and Server Security and Customer Security are at great risk. As around 35 of the total 113 vulnerabilities found regarded these 2 vulnerabilities in some manner, the probability of this risk can be considered very likely, and while the impact may not be extreme, even a major impact means high risk. So, I would give it an urgency-score of very urgent.
- The second one should be the cross-site scripting vulnerability. If malware is allowed to be injected into the network and subsequently to the devices, both the Network and Endpoints are at risk. Around 15 of the total 113 vulnerabilities were related to cross-site scripting, putting it in the probability section of moderate, and because the risk directly impacts the enterprise, its impact is extreme, meaning high risk. So, I would give it an urgency-score of urgent.
- The third vulnerability is that the bank shares users information with 3rd parties that are both local and overseas. This puts critical information at great risk, as it travels through multiple nodes which may or may not be secure, and attackers could simply change the passing data, or capture it for extortion. However, this does not impact the enterprise as much and therefore falls into the minor impact category, while the probability of it being very likely, as it happens for almost all users. This puts it in the medium-risk category. So, I would give it an urgency-score of moderately urgent.
- The next one would be the bunch of vulnerabilities caused due to older versions of software, or insecure 3rd party software being installed into local machines. This means that employee devices and system administrator devices are at risk (personal devices included). An attacker might use these vulnerabilities to get into the enterprise network, move laterally, and basically control everything. These vulnerabilities, however, were not as prevalent and therefore the probability score would be unlikely. But because this is a very serious vulnerability, it has an impact on the enterprise that is extreme, and that puts it into the medium-risk category. However, as the risk is quite dangerous according to me, I would give it an urgency-score of urgent.
- Finally, there are vulnerabilities that also affect the availability of resources: the DoS and Buffer Overflow attacks. They put the employees and customers availability at risk which might even lead to loss or stealth of data due to network congestion. These vulnerabilities appeared very rarely, and hence fall into the rare category, and while they can impact the organization if exploited on a large scale, they generally don’t pose a serious threat, putting them into the moderate impact category. This puts these vulnerabilities into the low-risk category. That gives them the urgency-score of not urgent.
VIII. Techniques to mitigate these risks
- For mitigating the first set of risks, better and more checks should be placed while accessing a server or an AS. Employees should be trained in using security software and writing secure code. Customers on the other hand should be constantly updated about any vulnerability that may arise in their applications and easy ways to either mitigate them or avoid them.
- To mitigate the second set of risks, better network firewalls and intrusion prevention systems should be kept in place. A good and secure event logging system should be installed that constantly keeps a record of any such happenings so that they can be avoided in the future.
- To mitigate the third set of risks, the enterprise should implement stricter privacy and data sharing policies. If that causes loss to the business, they should at least implement better encryption and data transport schemes that do not give out information even if packets travel through insecure nodes.
- For the fourth set of risks, regularly updating the software should be made mandatory, and if not manually, it should be done automatically via scripts run by the system admin. System admins’ devices should be protected with extra care and as much security as possible because they can always serve as entry points to the whole system if not protected. Customers should also be encouraged to come up with better and safer credentials so that attackers do have a hard time cracking them.
- For the final set of risks, implementing reverse proxies can prove to be very useful to avoid and mitigate DoS attacks. These proxies split the incoming rush of requests and data into smaller, more handleable fractions that can be dealt with, by the IT staff. To mitigate Buffer Overflow attacks, appropriate system scanners should be kept in a place which keeps looking for any malicious code that might be unauthorized to execute and thereby cause harm.
IX. Controls
The ensuing discussions will contain risk control strategies and techniques that are descendingly ranked in order of effectiveness, also considering the level of risk deduced from the Probability-Impact matrix. Given below are 2 tables, with one depicting the number and type of risks, and the types of cost that they incur, while the other depicting a comparison between risks and their controls to give you an overview.
Table VI
Control types and their numbers
Control-type | #Controls | Cost |
Preventive | 14 | Costly operation and implementation |
Detective | 4 | Cheap operation and implementation |
Forensic | 1 | Cheap operation, Costly implementation |
Audit | 1 | Cheapest operation and cheap implementation |
Table VII
RIsks and their best-possible controls
Risk | Control | Control-type |
Application and end-point vulnerabilities | Enforce stricter rules | Preventive |
Cross-site scripting | Implement content-security policies | Preventive |
Older hardware and software versions | Regular updation and replacement | Preventive |
Inefficient business practices | Sharing the least info with 3rd parties | Preventive |
Availability attacks | Implementing reverse proxies | Preventive |
- Controls to mitigate previously mentioned risks
The controls discussed below (applies to the sub-points as well) are ranked in descending order of effectiveness while also considering the level of risk deduced from the Probability- Impact matrix.
NOTE! The internal numbering starts from 1 every time. It does not mean that it is the absolute rank. It is the rank relative to others in the points.
- To control the risks that arises due to vulnerabilities in endpoint devices belonging to their employees, customers and partners and the applications running on them, JP Morgan Chase can do the following:
- Enforce stricter rules on the Chase mobile application that make a device select its server only after meticulous verification of its credentials. This control is a preventive control, as it will prevent malicious servers from performing a Man-in-the-Middle attack.
- Store users login credentials only after encrypting them with a secure encryption algorithm like AES-128 and store the keys in a secure manner as well. This is a preventive control as well because it will ensure that an unauthorized user is not able to access the data.
- Build application-specific scanners that periodically scan an application for loopholes or exceptions that can be taken advantage of and alert the user about them. They may not be present in the infant application, but updates may bring them along. This is classified as a detective control.
- Train employees to be mindful of security standards like those recommended by NIST, MITRE, etc. while designing application architecture, and deploying applications. This is a preventive control due to the fact that a strong and sturdy architecture means a lesser probability of a successful attack on the application itself.
- Next, to control the risks initiated by the vulnerabilities in networks and endpoint devices, that cause cross-site scripting, the following can be done by the enterprise:
- Ensure that HTML/XML documents are securely written, by never inserting untrusted data in them except in trusted locations. A list of rules that define where they can be inserted is given in the following link [13]. This is a preventive control as it will lessen the ease with which an attacker can perform cross-site scripting and thereby reduce its probability as well.
- Implement a Content Security Policy [13]. It is a mechanism that has been defined for browsers on the client side, that allows them to whitelist certain sources. Only these can then execute or render the resources of their website, ensuring confidentiality and integrity of their data at a certain level. This is a preventive control because it will block unauthorized access to web app resources, and therefore prevent any malicious scripting.
- Check the logs that have been generated over a period of time to look for interesting changes made in the XML/HTML code of the web page. There might be some changes that some unauthorized attacker may have made. These changes may have been too trivial to get explicitly noticed, but some probing could detect them. This is an audit control as it investigates the presence of a risk by scanning logs.
- They can also employ Penetration Testing teams that periodically come and test the enterprises infrastructure for penetrability. If any points of weakness are discovered, they can alert the enterprise about them. This can be called a detective control as it generates alerts and notifies urgent changes to the organization, which can then make preventive changes.
- This set of risks is initiated by the vulnerabilities that are caused due to older versions of hardware and software and negligence of employees and system architects. It can be controlled by doing the following:
- Being aware of the versions of all the hardware systems and software applications and ensuring that they are updated to their latest and most secure versions. Ideally, these should be those that the manufacturers either use for themselves or recommend to their customers. Most of the times, manufacturers are very quick in responding to a glitch or loophole in their product and provide frequent patches and updates for the same. This is a preventive control as it will stop attacks like SQL injections or static code running on employee devices.
- Customers should be informed about and encouraged to come up with better and more secure credentials that are not easy give-outs to brute-forcing attackers. This could fall in both, the preventive and detective category. Preventive, as it would safeguard the user systems from the aforementioned attacks, and detective, as users can always generate alerts about incidents and send them as feedback to the enterprise.
- Installing and running popular IDS/IPSs like Snort, or even basic detection and prevention techniques like Layer 2 port filtering, Layer 3 IP filtering, etc. so that if any attacker tries to gain illegal access to the enterprise infrastructure or data, he can be detected and appropriately blocked. This fall under both the preventive and detective categories.
- The next set of risks that arises due to vulnerabilities in the organizations business practices and compromise their own and their customers' data, could be controlled by doing one or more of the following:
- Sharing the least amount of information possible with 3rd parties or even partners. If utterly necessary for business, ensuring that they are capable of receiving and handling it in a secure manner. It is often the smaller and weaker 3rd parties that are more vulnerable to all kinds of attacks. This is a preventive control as it will secure any channels that the enterprise is connected to and any branches that it has, thereby blocking successful attacks from potential attackers.
- If sending critical information to different countries, be aware of the paths that it can take and potential threats that may be present around them. Secure the data via strong encryption and keep integrity checks in place. Also, use protocols that have a reputation for securely transacting data over most channels. This is a preventive control as it prevents active and passive threats from ASs or malicious routers that route the information passing through them.
- Continuing from the above-mentioned control, keeping a log of the network trace of that critical information. This can later be used as a knowledge base to prevent and detect probable threats. This classifies as a forensic control as it involves logging changes and crucial meta-information (information about information).
- The final set of risks that arises due to bugs in software code like dereferenced NULL pointers or 3rd party drivers that make attacks on availability easier could be controlled by doing one or more of the following:
- The Denial of Service attack can be prevented by using reverse proxies that split incoming packets into smaller fractions that are more manageable. This measure is a preventive control as it prevents attackers from flooding the enterprise’s internal and external network channels with useless requests.
- To control the risk of BufferOverflow attacks, the code should be written in a manner that either doesn’t allow for inputs that cause BufferOverfow, or detect invalid inputs as they come and refuse them. This is both a preventive and a detective control as it can both prevent a BufferOverflow from happening, and alert the system admin and the user if such an input is detected.
- They can also install compiler tools like StackShield or StackGuard [14] that can alert an employee for a probable BufferOverflow while he/she codes the application. This can be seen as securing the most fundamental part of the application at a very early level, thereby significantly reducing the chances of an attack on the base code. This is a preventive control facilitated by detection tools.
X. Budgeting and cost
There have been many risks to many organizations in the past that have come back to bite them because they have not tended to those risks. Budgeting risk control is very essential to an organization as it gives an idea of what can be implemented and at what cost. This module will discuss about the budget of those controls that if implemented, could mitigate those risks
- Control Groups
Many of the controls that were defined in the previous module differ in their importance and value to the organization. Based on the same, they can be grouped into the following groups:
- Very important: These are controls which must be implemented by an organization to avoid risks that pose a serious threat to its very functioning.
- Enforcing stricter rules and more granular filters for server selection.
Cost: The cost to hire software engineers for creating such policies and others for developing and deploying them. The cost of buying necessary machines that will aid them in doing so.
2. Storing credentials and keys only after securing them with state-of-the-art security methods, like AES-128, SHA-4096, etc.
Cost: The cost of professionals that can develop and maintain such algorithms, computational resources required to run the same, network resources to communicate it, and lots of storage devices for the same. These devices can be geographically distributed to decrease single points of failure and increase security, therefore costing more maintenance money. There is also the cost of procuring and maintaining the physical space required to place these devices and machines.
3. Ensuring that the design of HTML documents is secure and that no critical data is inserted at unsecure places, or no untrusted data is inserted at an untrusted location.
Cost: The cost of employing people who can securely code the HTML documents, and the cost of deploying it.
4. Ensuring that all the software and hardware is fully updated and compliant with the latest security standards.
Cost: A very high-speed network connection that is robust enough to handle updates in all or even subsets of devices together.
Cost of implementing IDS/IPS at endpoints to scan for malware that may tag along with updates or that may arrive as updates.
Cost of training employees in using the new software.
Moreover, upgrading hardware means either replacing the existing hardware altogether or replacing only a fraction. Either way, it means training employees in using the new hardware and making the new devices compliant with the devices in the infrastructure that they are connected to. There is also the cost of carefully disposing off the old hardware and removing any data that resides in them before doing so.
5. Enforcing a Content Security Policy that allows client-side browsers to whitelist the sources that can execute or render their resources.
Cost: Cost of crawling websites that may pose potential threats, or designing a classifier that classifies requesting websites as safe or unsafe according to parameters like certificates possessed, protocols being used, the requests they send, etc. Implementing this on a large scale will prove to be even costlier.
The representative control-set for this group:
- Storing credentials and keys only after securing them via state-of-the-art schemes like AES-128, SHA-4096, etc.
- Ensuring that all software and hardware is updated and compliant with the latest security norms.
- Ensuring that the design of HTML documents is secure and that no critical data is inserted at unsecure places, or no untrusted data is inserted at an untrusted location.
Table VIII
Minimal Budget(Monetary Approximation)










Akhilesh Iyer 3 yrs
The entire report is featured on my LinkedIn page: https://www.linkedin.com/in/cyber-aiyer/