Problem Statement
Sketching is a basic ability of humans. Sketching is a way to make a visual representation of objects that are encountered in our world. Sketching does not rely on words to describe an object. Words can be limited to different languages and therefore not easily understood by all. This means that words are not universal. A visual representation of an object is a form of universal communication. Anyone who can see the picture can form an idea of what it is.
Correctly interpreting the picture can be more difficult. The existing deep learning architectures are geared more towards real image photos instead of sketches. This has led to trying to find more convenient deep learning frameworks. It depends greatly on how well or accurate the artist can sketch.
Objective
Our project had two goals. The first goal was the construction of the CNN and training of the model to accurately predict sketches from the TU-Berlin Dataset. The Tu-Berlin Dataset is licensed under a Creative Commons Attribution 4.0 International License. The goal was to create a CNN that could achieve the highest possible validation accuracy we could achieve. The second goal was to create a web page on which new sketches could be made and be predicted.
Dataset Used:
TU-Berlin Dataset:
This dataset consists of 20,000 images and 250 classes. We reduced the classes to 50 due to training speed. Google Colab allows for 12 hours of the training period. For 250 classes, 100 epochs took 7 to 8 hours while 50 classes took 2 to 3 hours. We split the data set into 75% training and 25% validation. For 50 classes, this resulted in 3000 training images and 1000 validation images for our project.
Project Analysis based on a Previous Result:
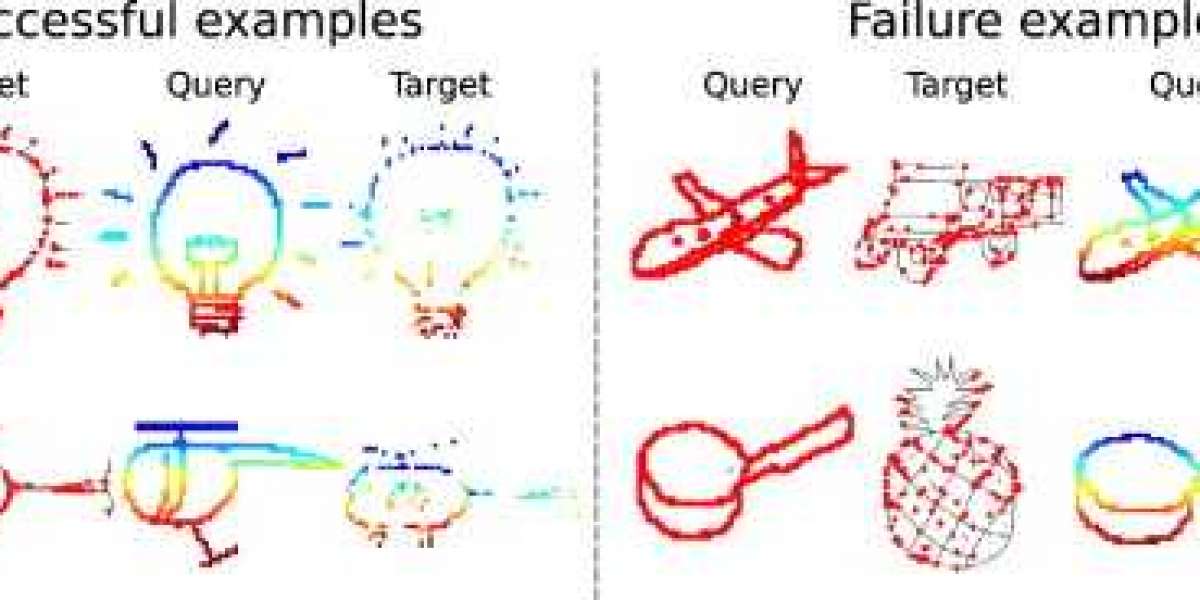
Among the TU-Berlin Dataset, there are 250 classes of objects or animals like an airplane, barn, or squirrel. Humans can predict the sketches that make up this dataset with an accuracy of 73%. By creating a CNN (convolutional neural network) that can interpret accurately the different sketches that are being drawn, it would be possible to communicate across languages and at a higher accuracy higher than 73%. The first CNN to accomplish this was Sketch-A-Net with an accuracy of 74.9% and was later modified with increased accuracy of 77.06%. Additional research has been done to further the classification styles and accuracy.
System Architecture:

Technologies Used:

Failed Models:
- We tried to create our own model but the model would not learn with the dataset.
- We then tried Sketch-A-Net Model. However, it would not learn either. Even though the Sketch-A-Net was created for this dataset.


Here, you can see the val_acc is so low.
Experimentation and Analysis:
We used 5 pre-trained models on the TU-Berlin dataset. VGG16, VGG19, ResNet50, InceptionV3, and Xception were the pre-trained models we used. We loaded the base models but then changed the outputs layers for all the models because the dataset had a different number of outputs (classes) than the original models. For VGG16 and VGG19, we set the base model layers to untrainable. This means that the original base model minus the output layer was frozen and the weights would not change for those layers. We did add new outputs layers to the VGG16 and VGG19 and these layers were trainable. The other models could be trained without freezing the weights of the base models.



Model selection:
We decided to use VGG16 as our final model because it had the highest accuracy without overfitting. Other pre-trained models were overfitting so we did not use them for the final model and the webpage.VGG16 has 16 layers and was designed to classify 1000 classes. The TU-Berlin Dataset has 250 classes and 20,000 images. We reduced it to 50 classes. We then split the data into validation and training. This gave us 3000 training images and 1000 validation samples.


Data Preprocessing:
Data Augmentation:
- Flip Horizontal, Change Rotation, Change Brightness, Divide Data by 255 to normalize
- Original Image size was 1,111 x 1,111. We used 150 epochs, 16 batch size, and an image size of 224 x 224.
Training the Model:
- We kept the base VGG16 model the same except we removed the output layer for 1000 classes and added an output layer to the do 50 classes.
- We also set the trainable parameter to False for the base model layers.

Prediction on Testing Data:

Web Page:
A webpage has been made by saving the trained model and using flask as a server and the frontend using HTML and CSS.












