During the Coronavirus Disease 2019 (COVID-19) pandemic, the usage of social media has significantly increased due to lock downs and social distancing policies. As more and more people rely on social media platforms for (mis)information about the disease, the circulation of fake news is raising a lot of concerns. This is because it poses a serious risk to public health as well as to the effectiveness of regulations being implemented by governments across the globe. Thus, it is extremely important to detect fake news. However, due to the rate at which new information is being generated online, it is extremely difficult to classify fake news manually.
Previous approaches on fake news classification are either supervised using large annotated data sets for linguistic features extraction, personality modelling, history of posts modelling, network analysis, and machine learning or unsupervised using user’s credibility and relationships between news article the words in them. When analyzing data from social media, we lack the annotations required for a supervised approach as well as features such as user credibility and tweet credibility that could be used to build personality models or tweet trustworthiness models as an unsupervised method. Therefore, an unsupervised approach seems most sustainable to analyze social media content.
Data Collection
In this article, the dataset used is a collection of 100 million tweets (January - April) from Twitter extracted using Hydrator. All these tweets contain coronavirus/covid-19 or any other variation of the disease name in their text. This dataset is randomly sampled and filtered by English language only which gives us a total of 6.5 million tweets. This dataset is then used for fake news classification.
Classification Methodologies
Since I wanted to explore unsupervised approaches, I decided to create a reference dataset composed of content classified as fake news by World Health Organization. The dataset consisted of the following categories:
• Garlic/Bleach cures coronavirus
• Drinking hot water/vinegar kills coronavirus
• Sunlight kills coronavirus
• Coronavirus was created in a Wuhan lab
• Coronavirus is a bio-weapon
• Bill gates is responsible for coronavirus
• Coronavirus causes fibrosis etc.
Using this reference set, 3 different methodologies were explored:
Set Similarity Measures
I used three set similarity measures: Character-based Jaccard Index, Word-based Jaccard Index and Tversky Index. Character-based Jaccard Index classified every letter of a tweet as a unique element of a set. The problem with this approach was that a tweet from our data set incorrectly matched with a fake tweet from the reference data set even if these tweets were not similar in terms of meaning and words. This was because these two tweets could have the same set of letters but entirely different words. To resolve the issue of word similarity, we tried using Word-based Jaccard and Tversky Index. These methods classified every word (instead of a letter) as a distinct element. However, just like character based Jaccard, this approach resulted in heavy penalization for tweets with same meaning but different phrasing, making these methods unviable for our classification task. Another limitation of all aforementioned set similarity approaches was that they only worked when tweets being compared were of similar length. Overall, it resulted in a ~15% accuracy (true positives/total tweets) only. Thus, I decided not to move forward with these similarity measures.
Doc2Vec
In this approach, I trained a Doc2Vec (Unsupervised ML) model on tweets with character length 120 ( 650k tweets); this ensured that the vectors were formed from tweets with a decent amount of content. The model had a vector size of 30 and it ran for 140 iterations. The model characteristics and size of the training data set were chosen such that they maximized the accuracy and did not cause any time constraints for this article. This model was fed with the compiled data set of reference tweets and it returned the best vector matches from the extracted tweets data set. This method, although not perfect for fake news detection, was able to classify the tweets by topic (e.g. a fake news about garlic returned a tweet about garlic which was not necessarily fake news) with a 35% accuracy (manual evaluation on top 10 matches for 100 proven fake tweets).
Keyword Classification
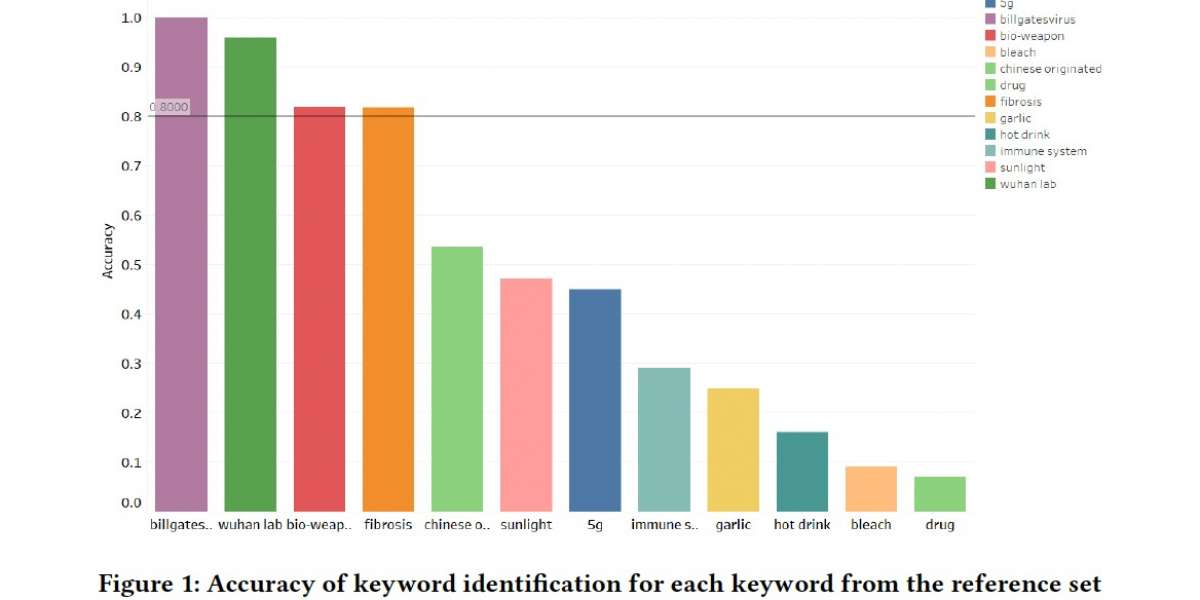
After discarding the aforementioned 2 approaches, I decided to extract tweets using keyword identification. I used the reference set to create a list of fake news keywords. This list was then used to extract tweets from the tweets data set (e.g. all tweets containing the word ‘garlic’, ‘bleach’ etc. were extracted). These tweets were then manually checked for fake news and categories with 80%+ accuracy were used for further analysis. The accuracy of each category and distribution of tweets for categories having accuracy greater than 80% can be seen in Fig. 1.
In conclusion, I believe that the set similarity approach is not suited for this application and that the Doc2Vec approach still has some room for improvement (increase in dataset size, number of iterations). Although Doc2vec might not reach the accuracies achieved by keyword classification, it is still worth exploring with tuned hyperparameters. While keyword classification performs best and gives an accuracy of 80% for most categories, the categories with lower accuracies can be processed using a negation algorithm which will separate "garlic is the cure" from "garlic is not the cure" resulting in a higher accuracy for fake news.










