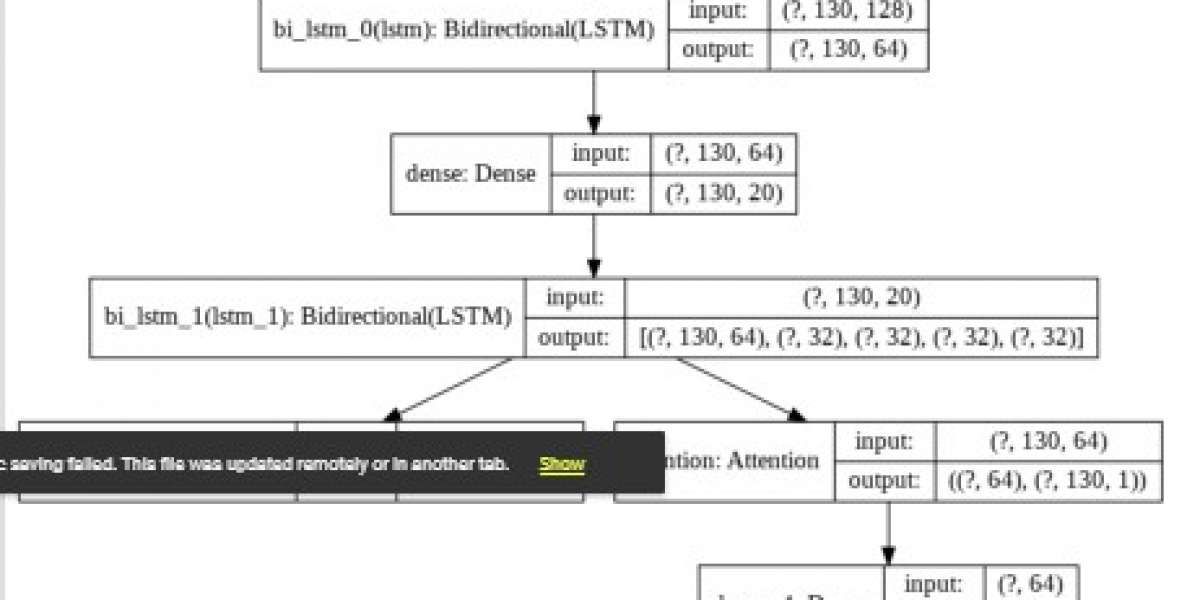
The deep learning model used in this project is Hierarchical Neural Attention Encoder. The encoder takes into consideration all the previous network attack events so that it can learn by itself and predict accordingly. The baseline models propose LSTM to solve this problem. While LSTM has proven successful for sequential data input problems, it has many problems. One of the biggest drawbacks of LSTM is that it can only compute up to hundred input sequences at time. Also ,since, it is based on RNN, it consumes a lot of system resources due to its complex structure. Therefore, this project proposes designing Hierarchical Neural Attention Encoder which would provide an advantage over the tradition LSTM models. Hierarchical Neural Attention Encoder consists of Bidirectional RNN coupled with Attention Network. The Bidirectional RNN will be used to determine the meaning of sequence of words and the Attention network would be used to return weights for each word. Attention network identifies only important features from all other noisy features which are not required in analysis. It also has higher computational efficiency of computing 10,000 input vectors at a time. The model will be initially trained on large sets of data gathered from different sources like acunetix logs and logs generated by python script. Compared to LSTM model, this model based on Attention Neural Network gives better precision and Accuracy on Attack Prediction


Popular Posts
-
 How DORA Works? DORA Process in Details.
How DORA Works? DORA Process in Details.
-
 Nike Operations Management
Nike Operations Management
-
 250+ Amazing Free Services For Developers and Startups to ideate, build and deploy for free
250+ Amazing Free Services For Developers and Startups to ideate, build and deploy for free
-
 NETFLIX CONTINUES TO DOMINATE– HOW NETFLIX KEPT ON DOMINATING THE STREAMING INDUSTRY EVEN DURING COVID-19.
By Syed Zaidi
NETFLIX CONTINUES TO DOMINATE– HOW NETFLIX KEPT ON DOMINATING THE STREAMING INDUSTRY EVEN DURING COVID-19.
By Syed Zaidi -
 Linux Scheduler profiling
Linux Scheduler profiling


