Introcution
Machine learning and deep learning models have proved to be effective in many real-world applications. For example, Apple has Siri which can automatically set up alarm by purely listening to human sentences from users. Notes taking apps are able to recongnize hand written words and translate into texts. However, most of these applications that utilized AI tools require resources and techniques that are difficult to acquire for individuals or small corporation without CS background. There are still abundant problems that are potentially suitable for AI applications.
One of my ongoing projects is related to applying deep learning models to analyze conservational videos. Disruptive new technologies in wildlife research, such as aerial and underwater drone videos have shown great promise in providing detailed information compared to historical methods reliant on human observers. These technologies offer opportunities to obtain precise measurements of species distributions and densities, which will lead to a better understanding of factors that affect the population dynamics of species, especially those imperiled by human activities. However, manually processing thousands of hours of videos requires excessive labor and consequently inefficient. In this article, I will discuss some issues my team encountered while applying AI to biological video data.
Data Preprocessing
Reliable and accurate label annotations is crucial for well-performed machine learning and deep learning models. However, it is difficult for researchers to manually label all data properly, without certain prior knowledge of how machine learning model works. In the following paragraphs I will describe some issues regarding data labeling during my project work.
Label Annotation Quality
Labeling accurately is critical for machine learning models to learn optimal parameters from the data. Yet, people in other fields such as biology might have different definitions of "accurate" labels. For example, while annotating labels for video at 1 frame per second, biology researchers might decide to label the frame based on the majority labels within the next second. Yet, what really matters to machine learning models is the exact label of that specific frame, rather than the majority labels within one second, as the models only take that particular frame as the input to the models. It is slightly counterintuitive to people from other fields as they might think the labels should contain as much information as possible. Thus, it is necessary for people who are interested in applying machine learning models to discuss annotation details with computer scientists so that they can make the best use of these models.
Cost of Annotation
Since training machine learning models usually requires large amount of data, how the labeling is performed become one major issue; it is almost unlikely for researchers to annotate all labels manually by themselves. Due to financial concerns, sometimes labor-intensive workers are hired to process the data. Before proceeding with annotating labels, another issue comes up: how much data should we label? For example, for the action recognition task in video processing, researchers have to decide if they want to label with a slow frequency at 1 frame per second, or with a higher frequency at 10 frames per second. There is a trade-off between the quantity of annotated labels and the quality of the trained model. While it depends on cases to cases, in my opinion, it is worthwhile first trying on a relatively coarse temporal resolution and see how the model works. I would also suggest experimenting with weakly supervised learning to see how many labels are actually required. This issue is especially important when resources are limited.
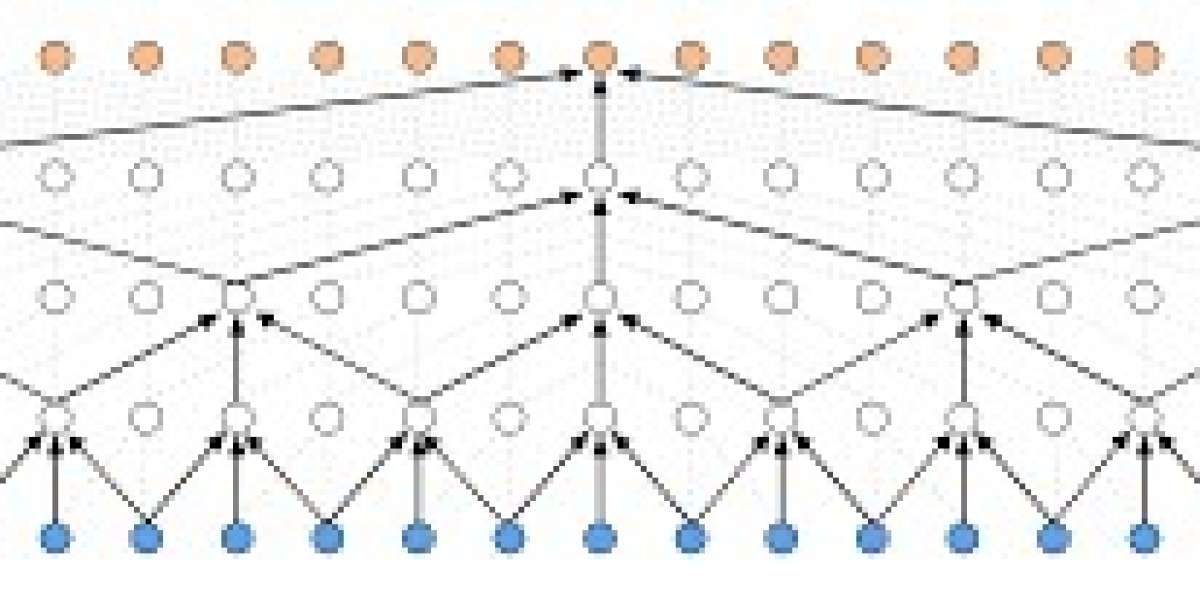
Choices of Model
In this section, I will talk about a few models that are common and popular for video classification. Unlike image classification, video classification not only concerns about the spatial properties of data, but also the temporal properties of data. Recurrent neurel network (RNN) is a good choice for time-related data. RNN is a model that accepts sequence of inputs (frames for video classification) and predicts labels (for each frame). The model can memorize useful information from seen data and make prediction using this temporal information in the model. However, there is one crucial disadvantage of RNN; RNN is not able to utilize the data from the future, relative to the target input (one frame for video classification). It might not be an issue for applications that need to work in real time as future data are not available. Yet, for those applicaitons which do not need to work in real time, it is usually effective to utilize the future data (future frames) while classifying video frames.
Another model happens to solve this issue: Temporal Convolution Network (TCN). The idea of this model is quite simple. TCN is applying 1D convolution over sequence of inputs. In video classification, TCN basically applies the convolution operations over the input frames. Consequently, the model can utilize the frames which are prior and succeeding to the target frame for final prediction. You can easily specify how many inputs you want the model to use for prediction (receptive field) by simply changing the input size and convolution kernel size. This model turns out to work really well in my project and I would recommend trying this model if you have not used it before for video classificaiton.
Summary
In this article I discussed some issues that people might encounter while applying deep learning models to their projects or problems, especially for video classificaiton. It is really important to consult with experts in AI or thoroughly read related references before applying AI tools.










