- Introduction
In this project we explored techniques to do semantic segmentation in an indoor environment and later used the results to help a turtlebot navigate an indoor area. To achieve this, we used Keras Image Segmentation Library and OpenCV.
Semantic segmentation is a pixel classification method. One of its prominent use is for autonomous driving. During autonomous driving it is important for the robot to know the environment it is operating in. We decided to test the feasibility of performing semantic segmentation on the turtlebot using video input from the Astra RGB camera and driving the robot based on the produced results .
- Semantic Segmentation
2.1 Initial Approach
At first we started by training a VGG_UNet model, which was one of the other provided semantic segmentation models in the Keras Image Segmentation Library.
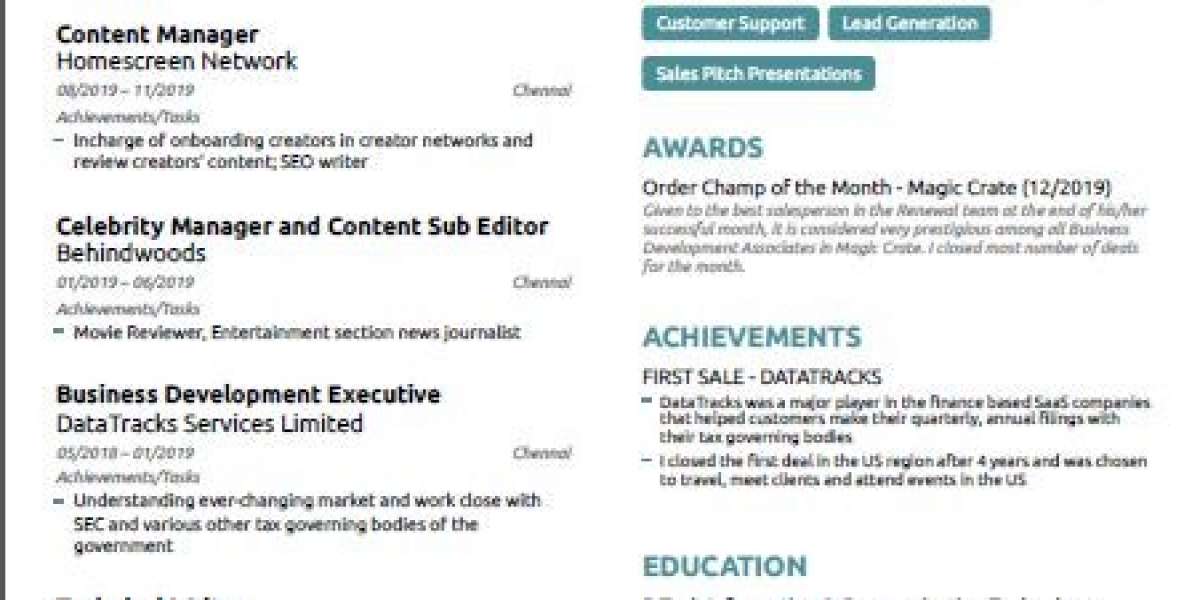
Training finished with an accuracy of around 88%. However, the images produced by the previously trained model proved too noisy for use with autonomous driving, as can be seen in Figure 1. For this reason, we decided to use the PSPNet model instead.
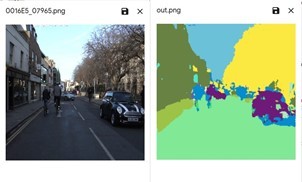
Figure 1. VGG_UNet output
2.2 Network Architecture
PSPNet first has a vanilla CNN to get the feature map of the input image and then it feeds the output of the feature map into pyramid parsing model to get the final feature map. Finally it uses the convolution layer to get pixel labelled image. A detailed representation is portrayed in Figure 2.
Figure 2. PSPNet model architecture
2.3 Training Dataset
The model was trained on the ADE20K dataset from MIT which contains images for both indoor and outdoor environments. Images in the dataset are densely annotated.
2.4 Results


Figure 3. PSPNet output
- Autonomous Driving
3.1 The Pipeline
Step-1: Once the segmented frame is acquired it is vertically cropped to half its original size this serves to limit the amount of area the script must operate on.
Step-2: Next we create a mask of the image by using OpenCV to turn all the path pixels white and non-path pixels black. This process is done via converting the frame from BGR two HSV
Step-3: Using the provided OpenCV functions and using the mask to determine the new color value of each pixel, we then use the dilate and erode functions to reduce the noise created during the masking process.
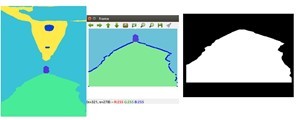
Figure 4. Breakdown of image pre-processing.
Step-4: Moving on we split the frame into three parts: left, center, and right. Each part corresponds to a movement option that the turtlebot could possibly take. Splitting the frame leaves us with three separate frames that we can operate on. Following this the frames are ready for processing by the movement algorithm.
To calculate the amount of whitespace in each frame we tried several different options. First we tried iterating through all the pixels in the frame and adding each white pixel to a counter, this approach had merit as starting from the top-leftmost pixel allowed us to calculate both the total number of operations and the distance between the Turtlebot and the current closest obstacle. While this approach led to accurate and useful results it proved to be computationally infeasible for autonomous driving. The approach took a large amount of time and visibly reduced the framerate of the OpenCV capture.
An alternative approach is to use the OpenCV countNonZero function, which intuitively counts all the non-zero pixel values in the frame. While it performs better than iterating over the whole image, this approach does not allow us to easily determine the distance to the closest obstacle in the same step. Under normal circumstances it would be trivial to gather the depth of the closest object from the Astra’s depth sensor, but the segmented image is resized to a different resolution making pixel address translation complex. At this point in time the movement algorithm still uses the method described first above. We chose to use this, even with the benefits of the second method, because it produced more accurate, albeit slower, results.
Step-5: Once values for each of the three frames are received the angular velocity of the robot is set towards the frame with the greatest whitespace area. The distance to the closest obstacle or hazard is later used to adjust the linear velocity of the robot. The separation of these two checks allows for the robot to turn or move independently, potentially allowing it to navigate its way out of corners, dead-ends, or other similar pathing obstacles.
- Results